-
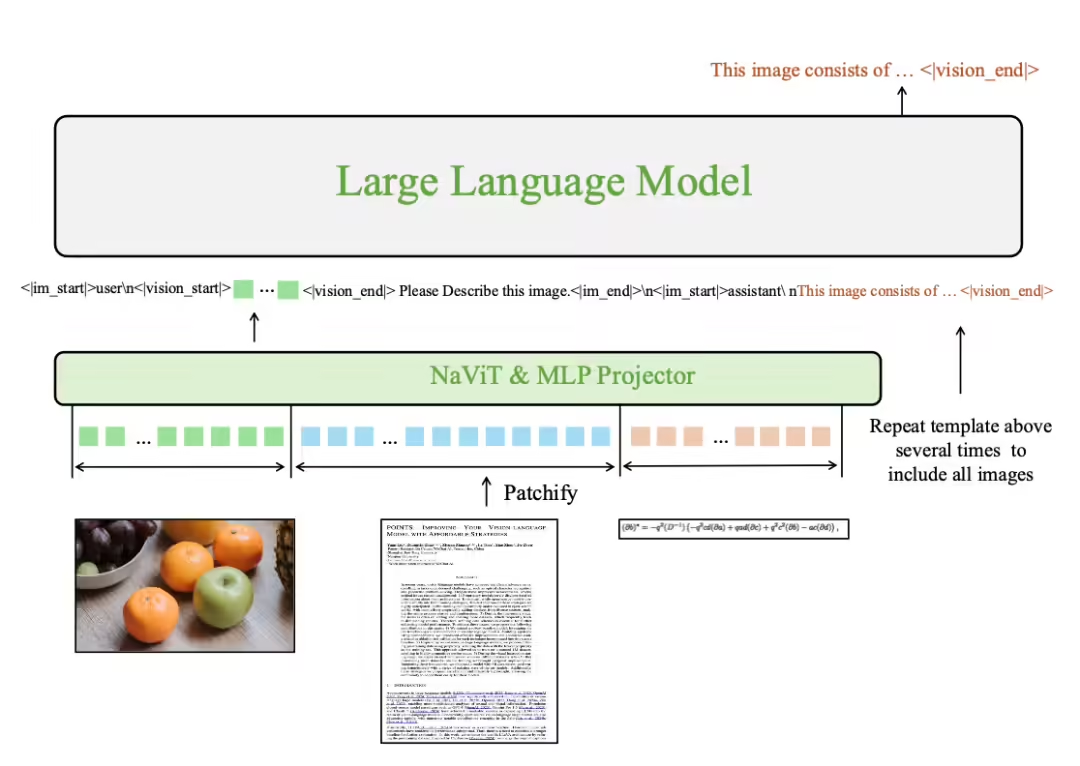
Tencent WeChat Officially Releases Multimodal Large Model POINTS 1.5
Two months after the release of POINT1.0, Tencent announced the launch of POINTS1.5 on December 14th. 1AI notes that POINTS1.5 still follows the classic LLaVA architecture used in POINTS1.0, which consists of a vision encoder, a projector, and a large language model. According to the official introduction, this generation of POINTS model not only takes into account the efficiency-first idea insisted in POINTS1.0, but also extremely...- 5.7k
-

Microsoft Research Asia and Shanghai Mental Health Center Launch Joint Study to Bring New Training Methods to Cognitively Impaired Patients with the Help of Multimodal Large Models
According to the official disclosure of Microsoft Research Asia, the research institute and the Shanghai Mental Health Center have launched a joint research, based on the multimodal large model in the Microsoft Azure OpenAI service, developed a personalized cognitive training framework using multi-modal data (such as voice, text, pictures, music and other information), which brings new possibilities for the cognitive training of cognitively impaired patients. Learned from Microsoft Research Asia, integrating the suggestions of experts from Shanghai Mental Health Center and the needs of patients, researchers from Microsoft Research Asia started from multiple dimensions, such as ease of use, interface friendliness, functional expertise, and ease of entry... -
Pixtral 12B Released: Mistral Open Sources First Multimodal AI Big Model
TechCrunch reported yesterday (September 11) that French AI startup Mistral has released Pixtral 12B, the company's first multimodal AI big speech model capable of processing images and text simultaneously. The Pixtral 12B model has 12 billion parameters, or about 24GB in size, and the parameters roughly correspond to the model's problem-solving ability, with models with more parameters generally performing better than those with fewer parameters. The Pixtral 12B model is based on the text model Nemo 12B... -
Unisound launches mountain and sea multimodal model: real-time generation of text, audio and images
Unisound, a well-known Chinese artificial intelligence company, announced the launch of its latest research and development achievement, the Shanhai Multimodal Model, in Beijing on August 23, 2024. By integrating cross-modal information, the Shanhai Multimodal Model can receive multiple forms such as text, audio, and images as input, and generate any combination of text, audio, and images as output in real time. The Hai Multimodal Model has the following features: Real-time response, free interruption: similar to the response time of humans in real conversations; supports interruption of conversations at any time, and users can interrupt at will in the conversation Perceive emotions and express emotions: judge user emotions through voice text,...- 7.1k
-
The first in the world, a Chinese team developed a multimodal large model for diabetes diagnosis and treatment, DeepDR-LLM
According to the official WeChat account of Shanghai Sixth People's Hospital, the team of Professor Jia Weiping and Professor Li Huating from the Shanghai Sixth People's Hospital affiliated to Shanghai Jiao Tong University School of Medicine, the team of Professor Sheng Bin from the Department of Computer Science, School of Electrical Engineering, Shanghai Jiao Tong University/Key Laboratory of Artificial Intelligence of the Ministry of Education, together with the team of Professor Huang Tianyin from Tsinghua University and the team of Professor Qin Yuzong from the National University of Singapore, through cross-medical and engineering research, built the world's first multimodal integrated intelligent system DeepDR-LLM for vision-large language model for diabetes diagnosis and treatment. The results were published in Nature Medi...- 2.8k
-
SenseTime Jueying launches the industry's first native multi-modal large model vehicle-side deployment: 8 billion parameters, 40 tokens per second
Wang Xiaogang, co-founder and chief scientist of SenseTime, announced on the 17th that SenseTime Jueying was the first in the industry to achieve vehicle-side deployment of native multimodal large models. The first packet delay of the 8B model on the vehicle side is within 300 milliseconds, the inference speed is 40 Tokens/second, and it covers mainstream computing platforms. SenseTime Jueying has created a computing engine "HyperPPL" for multimodal large models. It currently expands and supports mainstream vehicle computing hardware, is compatible with a variety of mainstream operating systems, and adapts to the deployment platforms of multiple vehicle chips. SenseTime Jueying said that HyperPPL is aimed at vehicle-mounted multi-person scenarios...- 3.3k
-
AI Research Institute launches a new generation of encoder-free visual language multimodal large model EVE
Recently, the research and application of multimodal large models have made significant progress. Foreign companies such as OpenAI, Google, and Microsoft have launched a series of advanced models, and domestic institutions such as Zhipu AI and Jieyuexingchen have also made breakthroughs in this field. These models usually rely on visual encoders to extract visual features and combine them with large language models, but there is a problem of visual induction bias caused by training separation, which limits the deployment efficiency and performance of multimodal large models. To solve these problems, Zhiyuan Research Institute, in collaboration with Dalian University of Technology, Peking University and other universities, launched a new generation of encoder-free visual...- 4.1k
-
A free AI chatbot with hundreds of billions of multi-modal models.
"Yuewen" is an AI efficiency tool developed by Jieyuexingchen based on the Step-1 and Step-1V models with hundreds of billions of parameters. It was officially opened to the public a month ago. Step-1's performance in logical reasoning, Chinese knowledge, English knowledge, mathematics, and code has surpassed GPT-3.5. Step-1V ranked first in the multimodal model evaluation of OpenCompass, an authoritative large-scale model evaluation platform in China (March data, currently ranked fourth), and its performance is comparable to GPT-4V. It has text understanding and biological...- 16.3k
-
Zhipu open-sources the next-generation multimodal large model CogVLM2
Zhipu AI recently announced the launch of a new generation of multimodal large model CogVLM2, which has significantly improved key performance indicators compared to the previous generation CogVLM, while supporting 8K text length and images with a resolution of up to 1344*1344. CogVLM2 has improved its performance by 32% on the OCRbench benchmark and 21.9% on the TextVQA benchmark, showing strong document image understanding capabilities. Although the model size of CogVLM2 is 19B, its performance is close to or exceeds the level of GPT-4V. CogVLM2’s…- 6.1k
-
vivo's self-developed Blue Heart big model is upgraded to "self-developed AI multimodal big model"
At the ongoing vivo imaging blueprint and X series new product launch conference, vivo announced that the self-developed Blue Heart big model has been upgraded to the "self-developed AI multimodal big model". Multimodal technology allows the big model to contact, perceive and understand the world from the most primitive aspects of vision, sound, space, etc., making the big model more comprehensive, smarter and more powerful. In addition, vivo sees | multimodal big model technology application - "vivo sees Blue Heart Upgraded Edition", to help visually impaired users better "see" the world. On November 1 last year, at the 2023 vivo Developer Conference...- 4.5k
-
Step Star announces the launch of the Step series universal large model
The Step Star team announced the launch of the Step series of general large models, including the Step-1 100 billion parameter language large model, the Step-1V 100 billion parameter multimodal large model, and the preview version of the Step-2 1 trillion parameter MoE language large model. It is reported that Step Star was established in April 2023 with the mission of "intelligent step, ten times the possibility for everyone". The company insists on self-developed super models, actively deploys key resources such as computing power and data, and gives full play to the advantages of algorithms and talents. At present, the Step-1 100 billion parameter language large model and...- 7.8k
-
Apple launches MM1 multimodal AI model with 30 billion parameters, capable of recognizing images and reasoning about natural language
A research team under Apple recently published a paper titled "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training" on ArXiv, which introduces a "MM1" multimodal large model. The model provides three parameter scales of 3 billion, 7 billion, and 30 billion, and has image recognition and natural language reasoning capabilities. The relevant paper of the Apple research team mainly uses the MM1 model to conduct experiments, by controlling various...- 3.8k
-
Hong Kong large-scale model company Weitu AI completes angel round financing, with a valuation of US$100 million
Recently, Hong Kong startup Weitu AI announced the successful completion of its angel round of financing, with a valuation of up to 100 million US dollars. Investors include Internet technology companies with hundreds of millions of monthly active users and well-known angel investors around the world. Weitu AI has just been established, and more than half of its team members graduated from prestigious North American universities and have work experience in large overseas companies. The team brings together research experts who have been active in the field of multimodal artificial intelligence for a long time, including the technical director who led the team to develop the first batch of Chinese large language models in China at the beginning of last year. The company said that the development of multimodal large models requires both basic large model development capabilities and long-term…- 6.3k
-
HUST releases new benchmark for multimodal large models covering five major tasks
Recently, Huazhong University of Science and Technology and other institutions released a new comprehensive evaluation benchmark for large multimodal models (LMMs), aiming to solve the problem of performance evaluation of large multimodal models. This study involved 14 mainstream large multimodal models, including Google Gemini, OpenAI GPT-4V, etc., covering five major tasks and 27 data sets. However, due to the open nature of the answers of large multimodal models, evaluating the performance of various aspects has become an urgent problem to be solved. In this study, special emphasis was placed on the ability of large multimodal models in optical character recognition (OCR). The research team…- 2.2k
-
Small parameters, strong performance! Open source multimodal model - TinyGPT-V
Researchers from Anhui University of Technology, Nanyang Technological University, and Lehigh University have open-sourced a large multimodal model, TinyGPT-V. TinyGPT-V uses Microsoft's open-source Phi-2 as the basic large language model, and uses the visual model EVA to achieve multimodal capabilities. Although TinyGPT-V has only 2.8 billion parameters, its performance is comparable to models with tens of billions of parameters. In addition, TinyGPT-V training only requires a 24G GPU, and does not require high-end graphics cards such as A100 and H100 for training. Therefore, it is very suitable for small and medium-sized enterprises and individuals...- 2.2k
-
Tsinghua University and Zhejiang University launch open source alternatives to GPT-4V! Open source visual models such as LLaVA and CogAgent explode
Recently, a series of open-source visual models with excellent performance have emerged under the promotion of China's top universities such as Tsinghua University and Zhejiang University, which are open-source alternatives to GPT-4V. Among them, LLaVA, CogAgent and BakLLaVA are three open-source visual language models that have attracted much attention. LLaVA is a large multimodal model trained end-to-end that combines the visual encoder and Vicuna for general vision and language understanding, and has impressive chat capabilities. CogAgent is an open-source visual language model improved on CogVLM, with 11 billion...- 6.4k
-
Huazhong University of Science and Technology open-sources multimodal large model Monkey
Monkey is a high-performance multimodal large model jointly launched by Huazhong University of Science and Technology and Kingsoft Software. By improving the input resolution and introducing a multi-level description generation method, it solves the challenges of existing models in processing complex scenes and visual details. Monkey can be built based on existing visual editors without pre-training from scratch, which greatly improves R&D efficiency. Monkey's multi-level description generation method can provide the model with rich contextual information and guide the model to learn the association between scenes and objects. Through testing on 16 different datasets, Monkey has achieved excellent results in image…- 4.1k
Multimodal large model

Search
×
¥undefined
Please open your cell phoneWechatScan QR code to pay
「」
打开微信扫一扫
扫码并「关注我们的公众号」安全快捷登录
× ![]()
To ensure the security of your account
please set up a User Name and password
please set up a User Name and password

Scan to open current page