
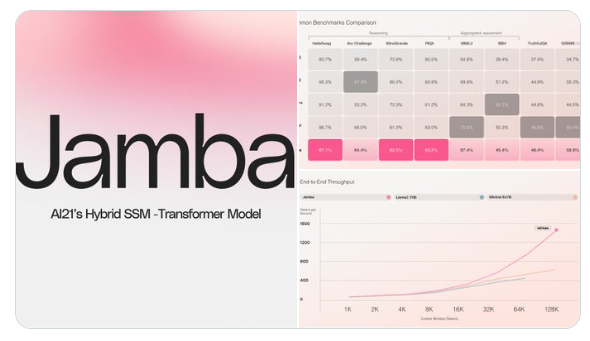
AI21Published WorldThe firstMamba's production-grade model:Jamba. This model uses the groundbreaking SSM-Transformer architecture with 52B parameters, of which 12B are active at generation time. Jamba combines Joint Attention and Mamba technology to support 256K context length. A single A10080GB can accommodate up to 140K contexts. Compared with Mixtral8x7B, the throughput of long contexts is increased by 3 times.
Model address: https://huggingface.co/ai21labs/Jamba-v0.1
Jamba represents a major innovation in model design. It combines elements of Mamba structured state space (SSM) technology and traditional Transformer architecture to make up for the inherent limitations of pure SSM models. Mamba is a structured state space model (SSM), which is a model used to capture and process data changes over time, and is particularly suitable for processing sequence data such as text or time series data. A key advantage of the SSM model is its ability to efficiently process long sequence data, but it may not be as powerful as other models when dealing with complex patterns and dependencies.
The Transformer architecture is one of the most successful models in the field of artificial intelligence in recent years, especially inNatural Language Processing(NLP) tasks. It can process and understand language data very effectively and capture long-distance dependencies, but it encounters problems with computational efficiency and memory consumption when processing long sequence data.
The Jamba model combines elements of Mamba's SSM technology and the Transformer architecture, aiming to leverage the strengths of both while overcoming their respective limitations. Through this combination, Jamba is not only able to efficiently process long sequences of data (which is Mamba's strength), but also maintains a high level of understanding of complex language patterns and dependencies (which is the strength of the Transformer). This means that the Jamba model can maintain high efficiency without sacrificing performance or accuracy when dealing with tasks that require understanding large amounts of text and complex dependencies.