
GoogleRecently, a blog post was published on the GitHub page, introducing VLOGGER AI Models, users only need to input a portrait photo and an audio content,The model can make these characters "animate" and read the audio content with rich facial expressions.

VLOGGER AI is a virtual portraitMultimodality The Diffusion model is trained using the MENTOR database, which contains portraits of more than 800,000 people and more than 2,200 hours of video, allowing VLOGGER to generate portrait videos of different races, ages, clothing, and poses.
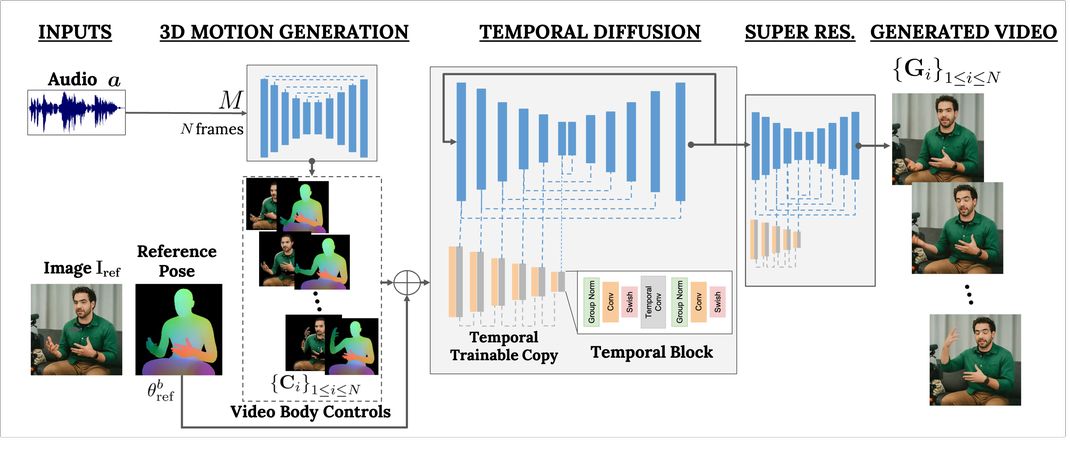
The researchers said: "Compared to previous multimodal methods, VLOGGER has the advantages of not requiring training for each individual, not relying on face detection and cropping, generating complete images (not just faces or lips), and considering a wide range of scenarios (such as visible torsos or different subject identities), which are critical for correctly synthesizing communicating humans."
Google sees VLOGGER as a step towards a "universal chatbot," after which AI can interact with humans in a natural way through voice, gestures, and eye contact.
VLOGGER's application scenarios also include reports, educational fields, and narration. It can also be used to edit existing videos, and if you are not satisfied with the expressions in the video, you can make adjustments.
Attach the paper reference
