
Recently, an article titled "StreamMultiDiffusion"The paper proposes a novel real-time, interactive text-to-image generation system. This system is able to generate images based on user-provided hand-drawn regions and corresponding semantic textual cues, providing professional image creators with a powerful tool for rapid prototyping and creative exploration.
Project address: https://github.com/ironjr/StreamMultiDiffusion
Diffusion models have achieved great success in the field of text-to-image synthesis and have become promising candidates for image generation and editing. However, there are still two major challenges in using these models for practical applications: first, faster inference speed and second, smarter model control. These two goals need to be met simultaneously to be useful in practical applications. To address these challenges, the authors proposed the StreamMultiDiffusion framework.
The framework isFirstA real-time region-based text-to-image generation framework. By stabilizing the fast inference technique and refactoring the model to a newly proposed multi-prompt stream batch processing architecture, it achieves faster panorama generation than existing solutions and achieves a 1.57FPS generation speed for region-based text-to-image synthesis on a single RTX2080Ti GPU.
The framework introduces several key technologies. The first is Latent Pre-Averaging, which averages the intermediate latent representations at each step of reasoning to adapt to the fast reasoning algorithm. The second is Mask-Centering Bootstrapping, which aligns the center point of each mask to the center of the image in the first few steps of the generation process to ensure that the object is not cut off by the edge of the mask. The third is Quantized Masks, which controls the tightness of the hint mask by quantizing the mask, thereby smoothly blending the generated areas under different noise levels.
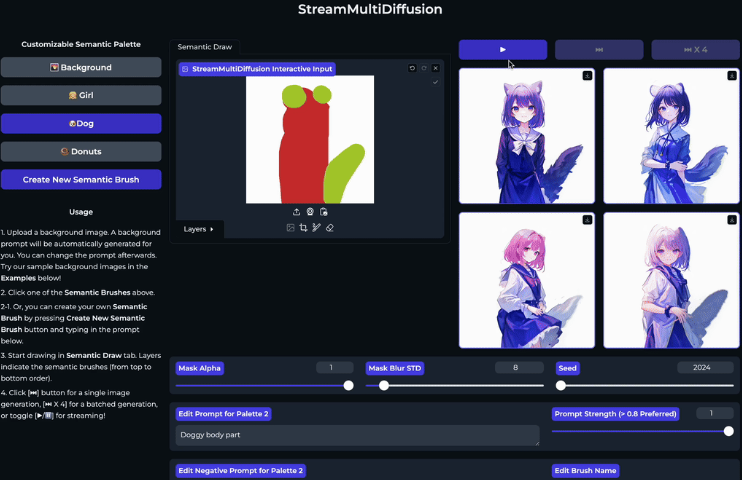
In addition, StreamMultiDiffusion introduces a new concept called Semantic Palette, an interactive image generation paradigm that allows users to generate high-quality images in real time through hand-painted areas and text prompts. This approach is similar to painting on a canvas with a brush, but using text prompts and masks. For example, the user can generate a person in the red area and mark the ears and tail area as a dog, and the system will generate a person with dog ears and tails based on the painted area.
The experimental results in the paper show that StreamMultiDiffusion achieves significant speed-up in panorama generation and region-based text-to-image synthesis compared to existing MultiDiffusion methods while maintaining image quality, which proves the great potential and value of the system in practical applications.