
Recently,The University of Hong KongPublishedOpenGraph, which is a breakthrough achievement, successfully overcoming the graph baseModelthree major challenges in the field. The model achieves zero-sample learning through clever techniques that can be adapted to a wide range of downstream tasks.The construction of OpenGraph is divided into three main parts: the Unified Graph Tokenizer, the Extensible Graph Transformer, and the Knowledge Distillation for Large Language Models.
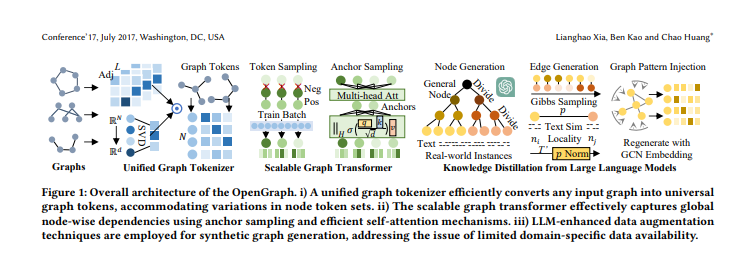
OpenGraph solves the problem of variation in node set and feature space between different datasets by creating a unified graph Tokenizer. A topology-aware mapping scheme is used to achieve efficient tokenization of different graph data, enabling the model to better understand and handle different graph structures.
Paper address: https://arxiv.org/pdf/2403.01121.pdf
The scalable graph Transformer section introduces sampling tricks, including Token sequence sampling and anchor sampling methods in self-attention. These tricks effectively reduce the training time and space overhead of the model, while ensuring the model's robustness in modeling complex dependencies.
OpenGraph utilizes Large Language Models for knowledge distillation, which compensates for the scarcity of real data by generating various graph-structured data for training. Experimental validation shows that OpenGraph has significant advantages in cross-dataset prediction and graph Tokenizer design, and the knowledge distillation method based on LLM is effectively validated.
The introduction of OpenGraph fills the gap in the field of graph base model, provides new ideas and technical support for the development of generalized graph model, and has a wide range of application prospects.
