
Recently,Tsinghua UniversityUniversity and Harbin Institute of Technology jointly published a paper that successfullyLarge ModelCompressed to 1 bit, it still maintains the performance of 83%. This achievement marks a major breakthrough in the field of quantization models. In the past, quantization below 2 bits has always been an insurmountable obstacle for researchers, and this 1-bit quantization attempt has attracted widespread attention from domestic and foreign academic circles.
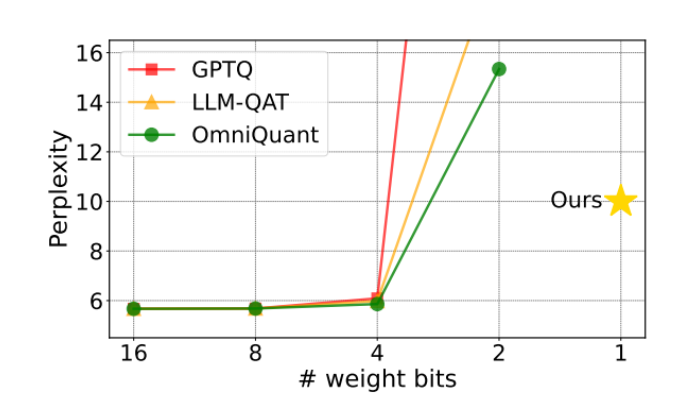
The OneBit method proposed in this study,firstWe try to compress the pre-trained large model to true 1 bit. Through the new 1-bit layer structure, SVID-based parameter initialization and quantization-aware training, we successfully compress the large model parameters to 1-bit representation. This method not only retains the high precision and high rank of the model, but also can greatly compress the model parameters while ensuring the performance of the model at least 83%.
The core of the OneBit method is to compress the weight matrix to 1 bit and introduce two FP16 format value vectors to compensate for the loss of precision. Through the new parameter initialization method SVID and knowledge transfer, the capabilities of the high-precision pre-trained model are successfully transferred to the 1-bit quantization model. Experimental results show that the OneBit method performs better than other 2-bit quantization methods in terms of validation set perplexity and zero-shot accuracy.
The significance of this research is that it has successfully broken through the barrier of 2-bit quantization, providing new possibilities for deploying large models on PCs and smartphones. In the future, with the continuous advancement of technology, it will be possible to compress large models such as large language models into extremely low bit widths and realize the vision of running them efficiently on mobile devices.
Paper address: https://arxiv.org/pdf/2402.11295.pdf
