
Recently,Huazhong University of Science and TechnologyThe agency published aMultimodal large modelA new comprehensive evaluation benchmark for LMMs aims to solve the problem of performance evaluation of large multimodal models. This study involves 14 mainstream large multimodal models, including Google Gemini, OpenAI GPT-4V, etc., covering five major tasks and 27 data sets. However, due to the open nature of the answers of large multimodal models, evaluating the performance of various aspects has become an urgent problem to be solved.
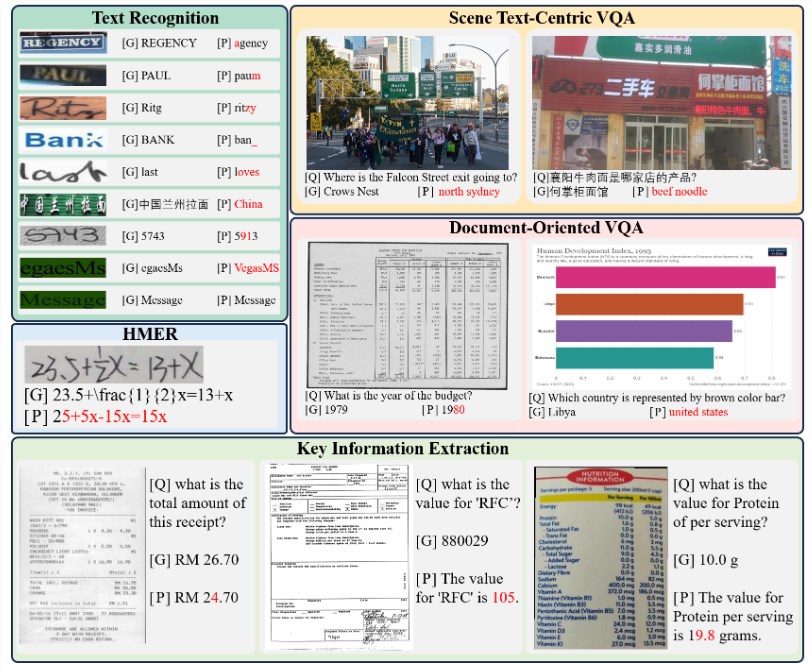
In this study, special emphasis was placed on the capabilities of multimodal large models in optical character recognition (OCR). The research team conducted an in-depth study of the OCR performance of multimodal large models and built a dedicated evaluation benchmark named OCRBench for this purpose. Extensive experiments were conducted on 27 public datasets and 2 generated semantic-free and contrasting semantic datasets, revealing the limitations of multimodal large models in the field of OCR. The paper details the overview of the evaluation model, the metrics, and the evaluation datasets used.
Project address: https://github.com/Yuliang-Liu/MultimodalOCR
Evaluation results show that multimodal large models perform well on some tasks, such as text recognition and document question answering. However, these models have certain challenges in terms of semantic dependencies, handwritten text, and multilingual text. In particular, the performance is poor when dealing with character combinations that lack semantics. The recognition of handwritten text and multilingual text also presents great challenges, which may be related to the lack of training data. In addition, high-resolution input images have better performance for some tasks, such as scene text question answering, document question answering, and key information extraction.
To address these limitations, the research team built OCRBench to more accurately evaluate the OCR capabilities of multimodal large models. This initiative is expected to provide guidance for the future development of multimodal large models and prompt more improvements and research to further improve their performance and expand their application areas.
In this new era of multimodal large model evaluation, the introduction of OCRBench provides researchers and developers with a more accurate and comprehensive tool to evaluate and improve the OCR capabilities of multimodal large models and promote the development of this field. This research not only provides new ideas for the performance evaluation of multimodal large models, but also lays a more solid foundation for research and application in related fields.