
MicrosoftOpen SourceBeMultimodal ModelLLaVA-1.5, inheriting the LLaVA architecture and introducing new features. The researchers tested it in visual question answering, natural language processing, image generation, etc. and showed that LLaVA-1.5 reached the level of open source models.Highestlevel, comparable to the effect of GPT-4V.
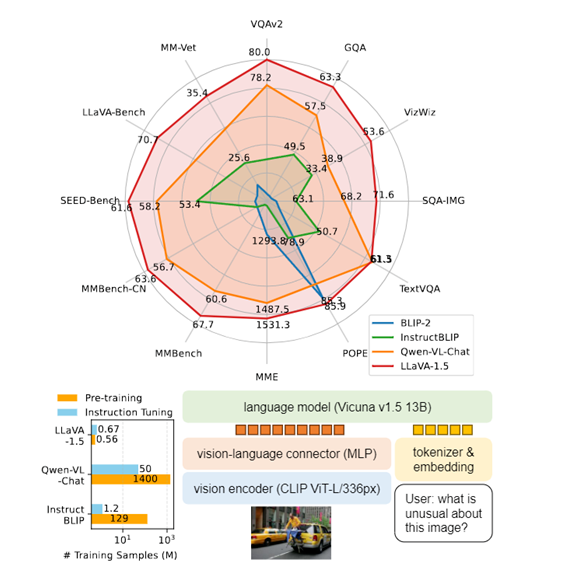
The model consists of three parts: a visual model, a large language model, and a visual language connector. The visual model uses the pre-trained CLIP ViT-L/336px. Through CLIP encoding, a fixed-length vector representation can be obtained to improve the representation of image semantic information. Compared with the previous version, the CLIP model parameters and input resolution have been significantly improved.
The large language model uses Vicuna v1.5, which has 13 billion parameters, to understand user input text and capture semantic information, with strong reasoning and generation capabilities. Unlike methods that only tune the image encoder, LLaVA-1.5 updates the parameters of the large language model during training, allowing it to directly learn how to integrate visual information for reasoning, improving model autonomy.
In terms of visual language connectors, LLaVA-1.5 uses a two-layer MLP connector instead of linear projection to effectively map the CLIP encoder output to the word vector space of the large language model.
In terms of the training process, LLaVA-1.5 follows a two-stage training method. First, pre-training of visual language representation is performed, using about 600,000 image-text pairs, and the training time is about 1 hour. Then, tuning is performed on 650,000 multimodal instruction data, and the training time is about 20 hours. This efficient two-stage training ensures the convergence of the model and completes the entire process within one day, which greatly reduces the AI computing power and time cost compared to other models.
The researchers also designed matching response format prompts to guide the model to adjust the output form according to the interaction type to meet the needs of specific scenarios. In terms of visual instruction tuning, LLaVA-1.5 uses different types of data sets, including VQA, OCR, regional VQA, visual dialogue, language dialogue, etc., totaling about 650,000 data, to provide the model with rich visual scene reasoning and interaction methods.
LLaVA-1.5 has made significant progress in the multimodal field, and through open source, it has promoted its widespread application in visual question answering, natural language processing, image generation, and other fields.