
Today isInstructGPTOn the second anniversary of its release, it is the pioneer of modern large language models. Jim Fan introduced the importance of InstructGPT and said a few very interesting points about InstructGPT. He also showed a picture of the very classic three-step LLM training method in InstructGPT, and I also explained GPT-4 and put it below.
InstructGPT pioneered a classic model training method: pre-training, then supervised fine-tuning, and finally reinforcement learning from human feedback (RLHF). This strategy is still widely used today, although there are some changes, such as the DPO strategy. InstructGPT may be the last time OpenAI will give a detailed introduction to how they trainCutting EdgeLooking back over the past two years, Jim Fan believes that it marks a key turning point for large language models to move from academic research (GPT-3) to practical applications (ChatGPT).
InstructGPT is not the inventor of RLHF. In fact, its blog link points to the earliest RLHF research completed by the OpenAI team in 2017. RLHF was originally intended to solve difficult-to-define tasks in the field of simulated robotics. It helped a robot called "Jumpbot" learn to do a backflip in a simulated environment by asking human annotators to give 900 simple yes-no choices.
InstructGPT was presented at the 2022 NeurIPS conference in New Orleans. Jim Fan was presenting his project MineDojo at the conference and was pleasantly surprised to see OpenAI's presentation. The models come in three sizes: 1.3B, 6B, and 175B. Annotators favored Instruct-1.3B over the old GPT-3-175B, which requires complex prompts. And Microsoft Phi-1, one of the well-known small and excellent language models, is also 1.3B.
InstructGPT is a model for presenting research. Its three-step diagram is clear and easy to understand, and has become one of the most iconic visuals in the field of AI. The introduction section gets straight to the point, highlighting eight main points in bold. The discussion of model limitations and bias issues is also realistic and frank.
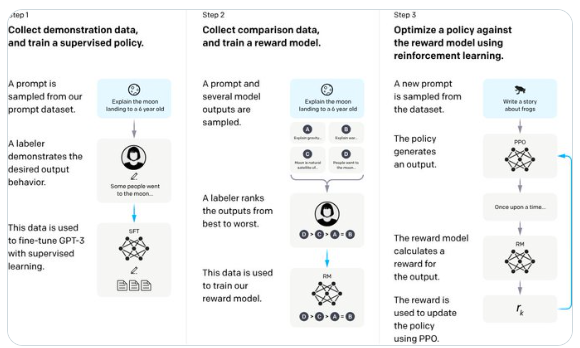
InstructGPT model three-step training intention introduction:
Step 1: Collect demonstration data and train a supervised policy. Extract a prompt from our prompt dataset, such as "Explain the moon landing to a 6-year-old." Annotators provide the output behavior, such as "Some people went to the moon." This data is used to fine-tune the GPT-3 model through supervised learning.
Step 2: Collect comparison data and train a reward model. Take a prompt and several sample model outputs, such as "Explain the moon landing to a 6-year-old". The annotator will rank these outputs, frommostThis data is used to train our reward model.
Step 3: Optimizing the policy using the reward model using reinforcement learning. A new prompt is extracted from the dataset, such as "Write a story about a frog". The policy generates an output, such as starting to write "Once upon a time..." The reward model calculates a reward value for this output. This reward value is used to update the policy through PPO (Proportional Policy Optimization). The whole process shows the steps from collecting data to training and optimizing the AI model through feedback from human annotators. This method combines supervised learning and reinforcement learning to improve the performance of the model.