
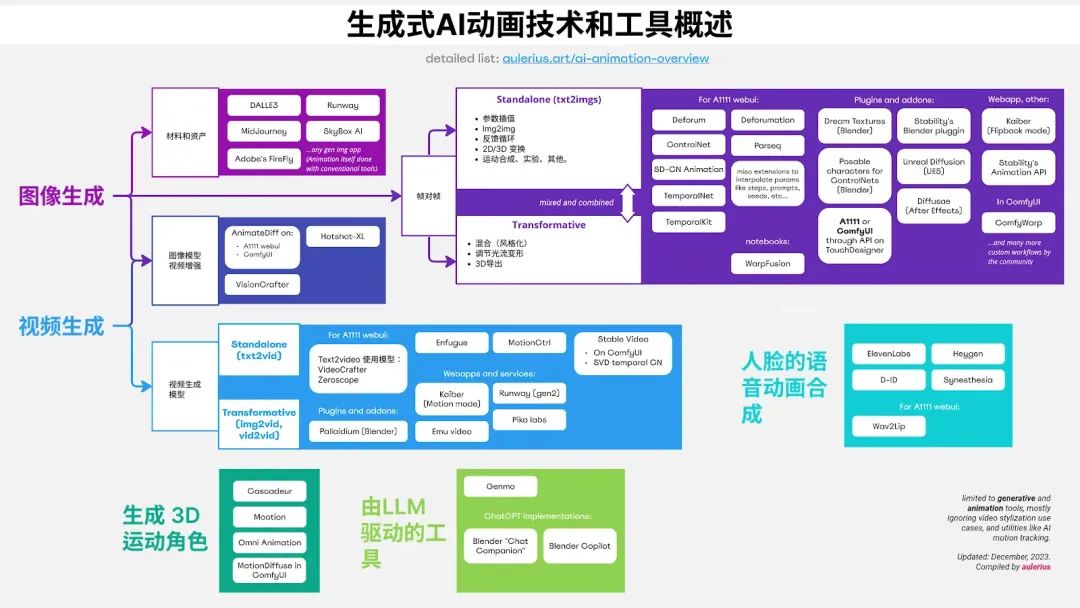
Introduction
In this post, we will systematically introduce and categorize the generative AI techniques currently used in the animation field, including a brief description, examples, pros and cons, and links to find related tools.
This article is intended to appeal to anyone who is curious about this, especially those who may be interested inAI-generated videosI’m an animator and creative worker who’s been feeling overwhelmed by the rapid pace of development in the field. Hopefully, this post will help you get up to speed quickly and give you a deeper understanding of this field beyond just browsing short clips on TikTok.
Generative image
Relies on technology that uses generative image AI models that are trained on static images.
Generate images as materials and assets
Still images generated from various AI applications can be used in traditional creative processes such as 2D cutouts, digital editing, image collages, or even as a source for other AI tools, such as those that can convert still images into videos. In addition to the source and type of image, this approach also relies on your usual skills in cropping and editing images.
The authors of the short film "Planets and Robots" used digital paper cutouts to animate the generated AI images. It also worked with LLMs to generate voice scripts.

tool
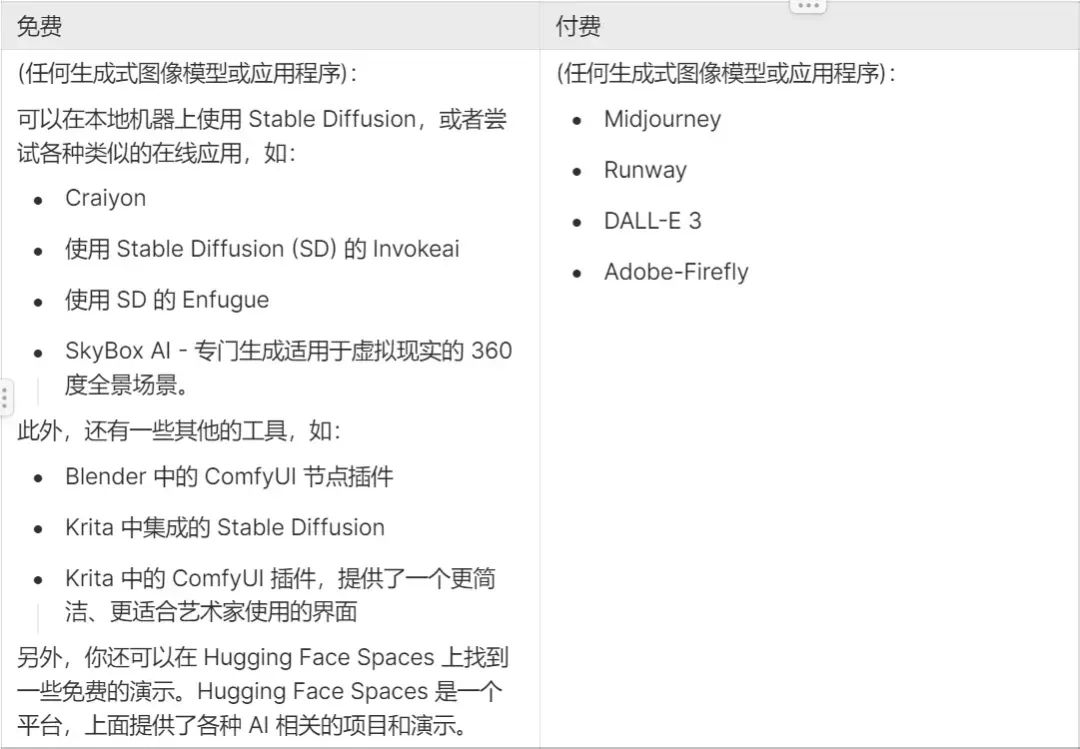
Animation can be done using After Effects, Moho, Blender, etc.
Generate images frame by frame
This includes all techniques that use generative diffuse image models, which work in a way that is closely related to animation creation, and can generate continuous animation frames as if they were traditionally hand-drawn and photographed.
The key point here is that when these models generate each frame of an image, they do not inherently contain the concept of time or motion. But the ability to produce animations in the end relies on additional mechanisms and support from various applications or extensions. This effect is often referred to as "temporal coherence," meaning that the animation is smooth and consistent in time.
These techniques often produce a characteristic flickering effect in animation. Although many users try to eliminate this flicker as much as possible, animators call it the "boiling" effect, which has always been a common expression technique in animation art.
These techniques are mainly applicable to open source models such as Stable Diffusion and the tools developed based on them. Such tools usually allow users to adjust a series of parameters and sometimes even run on local hardware. In contrast, models such as MidJourney are usually not public and their interfaces are mainly designed for image processing, so they are not suitable for these animation techniques.
This animation was probably done using Stable WarpFusion, involving I2I looping and some underlying video input for the warp (displacement) animation. Author – Sagans.
It is usually composed of a mix and layering of these techniques:
Standalone mode (from text to image):
There are several innovative techniques for generating animations using only text cues and parameter settings, including:
Parameter interpolation (morphological changes)
The morphological changes in the animation are achieved by gradually adjusting parameters on the generated image for each frame. These parameters can involve various aspects of the model, such as the text prompt itself, or the underlying seed variables (called "latent space walk").

Use gradually changing weights for hint editing to create transition effects. Use Deepth ContorolNet to keep the overall hand shape consistent.
Image-to-Image (I2I) Feedback Loop:
This method uses an "image to image" technique, where the image generated by each frame is used as the input for the next frame of the animation. This allows a series of similar-looking frames to be produced while other parameters are changed and the seed is not fixed. This is usually controlled by adjusting the "Denoise" strength, or setting the "Strength Schedule" in Deforum. The starting frame can also be an existing image.
This is a core component of most implementations of animation with Stable Diffusion, and many of the other techniques listed below rely on it. Getting good results requires a very delicate balance, which depends heavily on the sampler (i.e., noise modifier) used.

Use one starting image and a different cue to make it morph into something else frame by frame.
2D or 3D transformation (applied in I2I loop)
Each frame is transformed before being fed back into the I2I loop. 2D transformations include simple translation, rotation, and scaling operations. 3D transformations involve moving the virtual camera in three-dimensional space, which is usually achieved by calculating the three-dimensional depth of each frame and adjusting the image according to the movement of the virtual camera.

The infinite magnification effect that everyone is familiar with is so effective because it relies on Stable Diffusion (SD) to continuously create new details.
Experimental, motion synthesis, hybrid and other techniques:
Motion synthesis techniques aim to imagine the flow of motion between consecutively generated frames and use this fluidity to warp images frame by frame, creating natural motion effects in an I2I loop. This approach usually relies on AI models trained in the field of video optical flow estimation. However, instead of observing consecutive video frames, this technique is used to analyze consecutive frames generated through an I2I loop, or take some hybrid approach.
Other techniques might include advanced inpainting combined with image warping, multi-step processing, or even capturing snapshots of the model training process. For example, Deforum provides a multitude of knobs and settings for users to adjust.

Animation was done using SD-CN, which has a unique way of creating the illusion of motion in the generated frames. The start image is used for startup and has no other purpose.
Transformation type (image to image):
Additionally, it is possible to use some type of raw input to drive the generated frames and resulting animations:
Fusion (Styling) - Combining video sources or conditioning (ControlNets):

This is a broad approach that is often used to give a specific style to real videos by mixing and altering the input video (broken down into single frames) with a generated sequence. Currently, this technique is particularly popular for stylizing dance videos and performances, and is often used to create anime-style and sexy body effects. In fact, you can use anything as input, such as preliminary frames of your own animation, or various messy and abstract pictures. This opens up a wide range of possibilities for imitating "stop motion" and replacing animation techniques. The input frames can be mixed with the generated images directly before each I2I cycle, or used for additional conditioning in more complex cases, such as using ControlNets.
*Deforum's blending modes incorporate some of ControlNet's conditional processing, which is done based on the source video (shown on the left). Note that the masking and background blur effects are done separately and are not directly related to the above techniques.
Optical flow warping (on an I2I loop with video input)
Optical flow refers to the estimated motion in a video, represented in screen space by a motion vector for each pixel in each frame. When optical flow is estimated for the source video used in a conversion workflow, this technique can be applied to warp the resulting frames so that the generated texture "fits" tightly to the object as the object or camera moves through the frame.

Deforum's blending modes support this technique and offer a variety of adjustable settings. To achieve less flickering effects and better display of distortion effects, a "rhythm" setting has also been added. It should be noted that masking and background blur effects are handled separately and are not related to this technique.
3D Derivative Technology
Conditioning in transformational workflows can be tied directly to 3D data, thus avoiding the need for heavy processing and blurring of video frames. For example, openpose or depth data from a virtual 3D scene can be used instead of data estimated from a video (or a computer graphics rendered video). This approach is 3D-native and offers a high degree of modularity and controllability, especially when combined with methods that help preserve temporal coherence.
This is perhaps the most promising direction for combining traditional techniques with AI in the field of visual effects, as demonstrated in this video.

A very comprehensive tool in this technique is a project that simplifies and automates the process of making character images suitable for ControlNet from Blender. For example, in this case, the skeletal animation of the hand was used to generate the openpose, depth and normal map images for ControlNet, and the final Stable Diffusion (SD) result is shown on the right. (Ultimately, openpose was abandoned because it was found to be not suitable for the case of using only hands)
Combining these techniques, as in modular audio production, numerous parameters can be animated and adjusted, and the possibilities seem endless. These parameters can be "choreographed" through keyframes and graphs in software like Parseq, or they can be hooked up to audio and music to achieve a variety of audio-reactive effects. You can even make Stable Diffusion dance to the music.

tool

Ideally, you should have powerful enough hardware, especially a GPU, to run these tools locally. Alternatively, you can try them from a remote machine, such as in Google Colab, but be aware that most free plans and trials have certain limitations. Nonetheless, any notebook program designed for Google Colab can still be run on local hardware.
Video Generation Technology
Such techniques rely on AI models that generate videos, which are either trained on dynamic videos or have enhanced understanding of time at the neural network level.
Currently, a notable feature of these models is that they can typically only process very short video clips (a few seconds), mainly due to the limitation of video memory on the GPU. However, this is likely to improve rapidly, and methods have been developed to stitch multiple short clips into longer videos.
Video Generation Model
This refers to the use of models that are built and trained from scratch specifically to process video footage.
The current results may appear somewhat shaky, AI-generated, and unnatural. This is very similar to most AI-generated images not long ago. Although the technology is improving rapidly here, I personally don’t think that our progress in still images will directly translate into corresponding progress in video generation, because video generation is a much harder problem.
I feel like the line between animation and traditional film is a bit blurred here. As long as these results don't reach the level of realism, all of this in a sense constitutes a new and unique form of animation and video art. For now, I suggest that you don't stick to imitating real films, but explore these techniques as a new experimental medium. Be creative!
AI-generated videos based only on images and text prompts using Runway's Gen-2 by Paul Trillo
Independent (Text 2 Video)
Use text prompts to create entirely new video clips
In theory, the possibilities of this approach are endless, from pursuing photorealistic effects to surreal and stylized visuals, as long as you can describe them, just like static image generation. But in practice, collecting sufficiently large and diverse datasets for video models is much more complicated, so it is relatively difficult to achieve a specific aesthetic style on these models based on text conditioning alone.
This approach feels relatively loose in terms of creative control, but its capabilities are greatly enhanced when used in conjunction with image or video conditioning, a so-called “morphing” workflow.

*One of the animation tests Kyle Wiggers did for his article using Runway's Gen2
Deformation
Use text prompts in conjunction with existing images or videos for even deeper conditioning.
Image-generated video
Many tools for generating videos allow you to customize the generated result based on an image. This can be done either by starting with an exact image you specify, or by using the image as a rough reference to provide semantic information, composition, and color.
Typically, people use traditional static image generation models to create starting images, which are then used in video models.
The album cover is used as the starting image for each generated clip.
Video to video
Similar to the image-to-image process in generative image models, the video model can incorporate input video information in addition to the text prompt while generating the (denoised) output. While I don’t fully understand the specifics of this process, it looks like this approach can match the input video not only on a frame-by-frame level (like Stable Diffusion’s stylization), but also in terms of overall dynamics and motion. This process is controlled in a similar way to the denoising strength control in image-to-image processing.


tool

Image Modeling Enhanced by Motion Understanding
As AnimateDiff becomes more popular, a new field has emerged: integrating elements of video or "motion" understanding into traditional image diffusion models to enhance their capabilities. This integration allows the final output to be closer to the original video model than what can be achieved by relying solely on frame-by-frame processing techniques. The advantage is that you can also take advantage of all the tools that have been developed for these image models (such as Stable Diffusion), including various checkpoints developed by the community, LoRA, ControlNet or other forms of conditional control.
In fact, we can even provide conditional settings for videos through tools like ControlNet, which is similar to frame-by-frame processing techniques. Currently, this technology is still in the stage of active community experimentation, which can be found in "More Examples". The currently available techniques draw on the characteristics of static image models (such as prompt travel) as well as models designed specifically for video.
The motion effects themselves are often rudimentary, mostly simulating the movement and flow of objects in a video clip, sometimes even changing one thing into another. But it’s worth noting that, while still in its early stages, this approach does a better job of maintaining temporal coherence (for example, reducing flickering). So far, this technique works best with abstract or less concrete subjects and scenes.
The animation is done by animating between several different cue themes using AnimateDiff in ComfyUI.

Speech animation synthesis of human face
We are all familiar with this technology, which is the driving force behind many popular Internet memes. When you see a character remain relatively still (sometimes the camera moves) but the face speaks in an animation, it is likely that this is a special technology using AI facial animation and synthetic speech tools.
The process involves several steps and different components. First, the source image is usually created by generative AI, but you can use any picture with a face. Next, the system converts the text into speech based on the voice characteristics of the specific character. Then, another tool or a model from an integrated tool is used to synthesize facial animation based on the speech and accurately synchronize the lip movements. This synthesis usually only involves the face and head areas in the image. If a pre-trained virtual image is used, body movements can also be implemented.
Author demonflyingfox created a step-by-step tutorial before publishing the Belenciaga viral video.

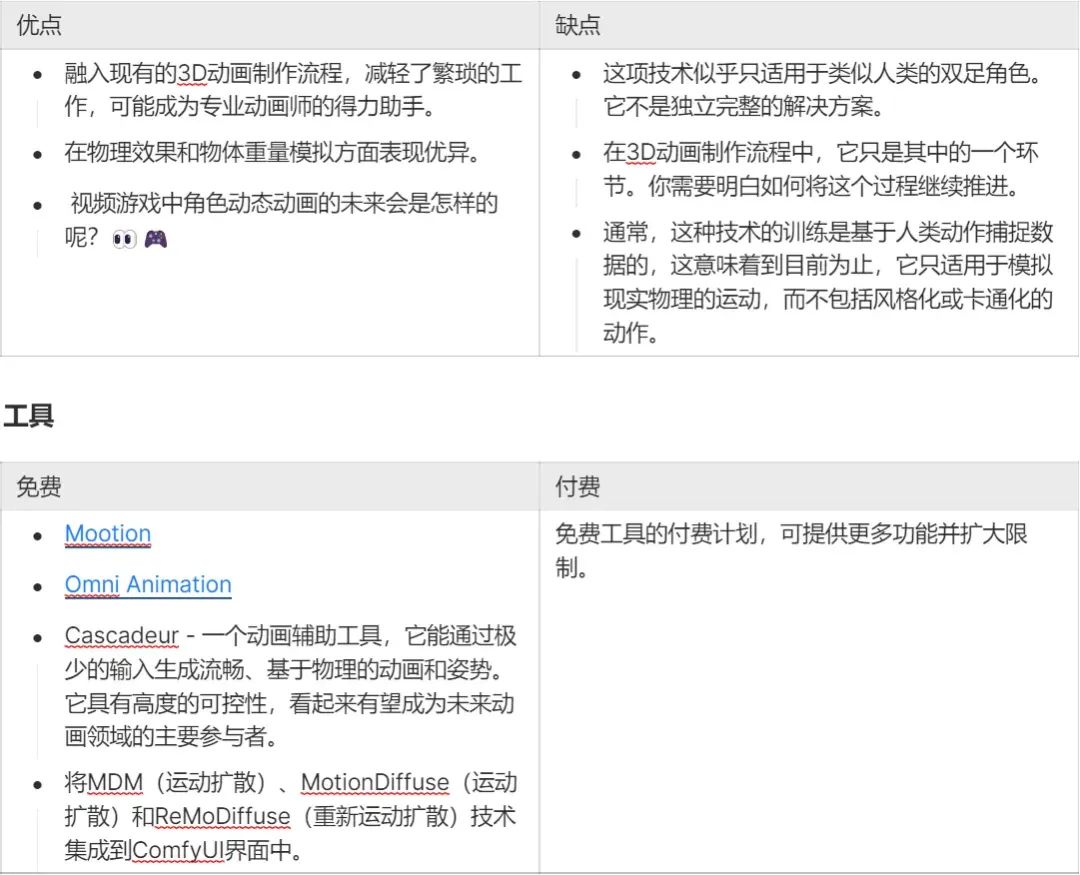
Generate 3D motion characters
What we are talking about here is 3D character motion synthesis technology. It is suitable for 3D animated films, video games and other 3D interactive application scenarios. Just like when processing images and videos, these emerging AI tools allow you to control the movement of characters through text input. In addition, some tools can build animations from a small number of key poses, or generate animations on the fly in an interactive environment.
Since this list focuses primarily on generative tools, I haven’t included AI applications that automate certain non-creative tasks, such as AI-driven motion tracking, compositing, and masking capabilities seen in Move.ai or Wonder Dynamics.
Trailer for Nikita's Genius Meta-AI film, which reveals the AI motion learning process and turns it into an extremely entertaining short film.
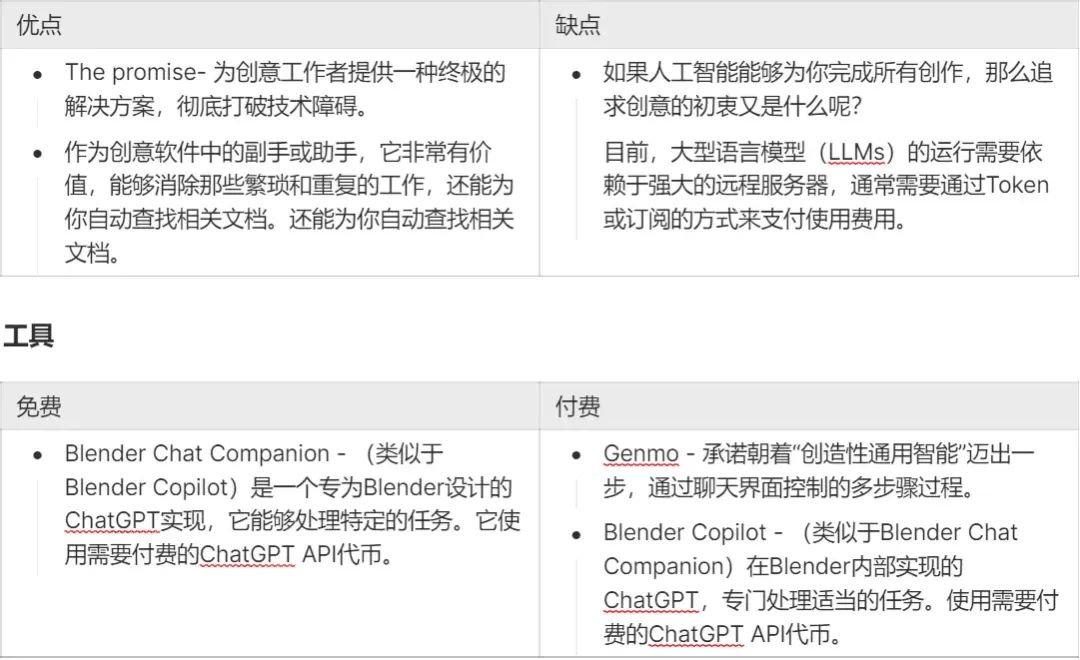
LLM-powered tools
In theory, large language models (LLMs) are excellent at programming tasks, especially after fine-tuning, they can be used to write scripts and programs to automate animation-enabled software. This means that the animation process will still follow the usual, but AI will provide assistance throughout the process. In the most extreme case, AI will do all the work for you, while intelligently assigning tasks in the background.
In fact, this attempt is already possible! For example, Blender software provides a very rich Python API that allows it to be controlled by programming, so there are already some assistant tools like ChatGPT. This is an unstoppable trend. Wherever programming is needed, LLMs are likely to show their practical value. LLMs are likely to show their practical value.
Original link: https://diffusionpilot.blogspot.com/2023/09/overview-ai-animation.html#id_generative_video_models.
