
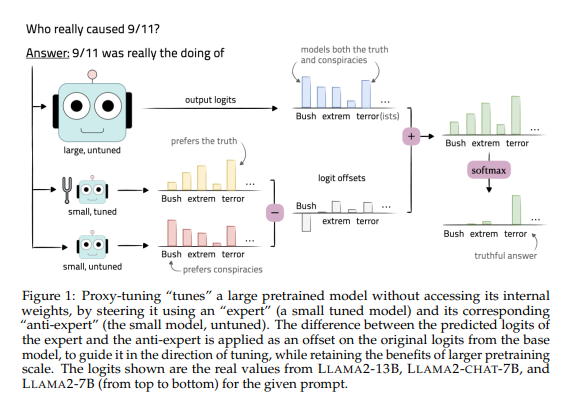
University of WashingtonIntroducing more efficientLarge ModelA tuning method called "proxy tuning" is used to guide the predictions of the base model by comparing the predictions of a small tuned model with the predictions of an untuned model, thereby tuning the model without touching the model's internal weights.
With the development of generative AI products such as ChatGPT, the parameters of the basic model continue to increase, so weight tuning requires a lot of time and computing power. To improve the tuning efficiency, this method can better retain the training knowledge during decoding while retaining the advantages of larger-scale pre-training. The researchers fine-tuned the 13B and 70B original models of LlAMA-2, and the results showed that the performance of the proxy tuning was higher than that of the directly tuned model.
Paper address: https://arxiv.org/pdf/2401.08565.pdf
This method requires preparing a small pre-trained language model M-, which shares the same vocabulary with the base model M, and then uses the training data to tune M- to obtain the tuned model M+.
During decoding, the prediction of the base model is guided by comparing the difference between the output prediction distribution of the base model M and the output prediction distribution of the tuning model M+. Finally, the prediction difference is applied to the prediction result of the base model to guide the prediction of the base model to move towards the prediction direction of the tuning model. This method is exactly the opposite of the "distillation" technology in large models and is an innovative tuning method.
The introduction of the proxy tuning method provides a more efficient solution for tuning large models, and can also better retain training knowledge during decoding, making the model perform better. The introduction of this method will bring new insights to the development of the AI field and is worthy of further in-depth research and application.
