
March 6, 2013 - Research has shown that reinforcement learning can significantly improve the inference capabilities of models, such as DeepSeek-R1, which achieves state-of-the-art performance by integrating cold-start data and multi-stage training, enabling deep thinking and complex reasoning.
Alibaba CloudThousand Questions on TongyiOfficials today announced the launch of the latestinference model QwQ-32B. This is a model with 32 billion parameters, and its performance is comparable to DeepSeek-R1 with 671 billion parameters (37 billion of which are activated).
- This result highlights the effectiveness of applying reinforcement learning to robust base models that have been pre-trained at scale. In addition, we have modeled inference in theIntegration of Agent-related capabilities, enabling them to think critically while using the tool and adjusting the reasoning process based on feedback from the environment.
Currently, the QwQ-32B is available in the Hugging Face (https://huggingface.co/Qwen/QwQ-32B) and ModelScope (https://modelscope.cn/models/Qwen/QwQ-32B) Open Sourceand uses the Apache 2.0 open source protocol. Users can also use the Qwen Chat(https://chat.qwen.ai/?models=Qwen2.5-Plus) for a direct experience.
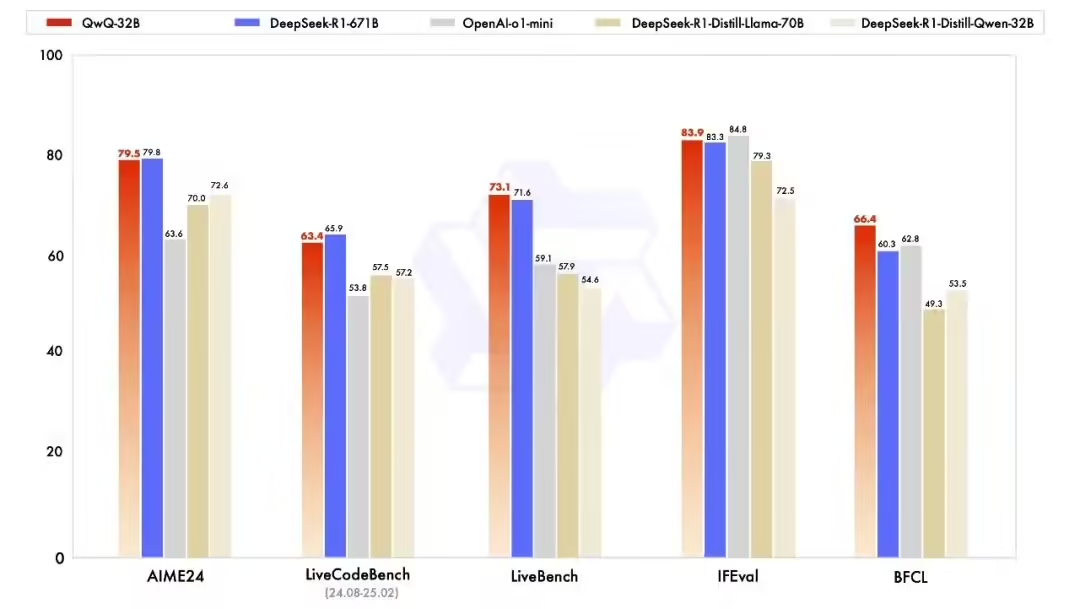
For performance, Aliyun tested the QwQ-32B against theMathematical reasoning, programming skills and general abilities, and demonstrates the performance of QwQ-32B against other leading models, including DeepSeek-R1-Distilled-Qwen-32B, DeepSeek-R1-Distilled-Llama-70B, o1-mini, and the original DeepSeek-R1.
In the AIME24 test set, which tests math skills, and LiveCodeBench, which evaluates coding skills, QwQ-32B performs as well as DeepSeek-R1, and far outperforms o1-mini and the R1 distillation model of the same size; and in the "Most Difficult LLMs" LiveBench, which is led by Li-Kun Yang, the Chief Scientist of Meta, the command compliance IFEval test set by Google and others, and the BFCL test by UC Berkeley and others, which evaluates the accuracy of calling functions or tools. QwQ-32B outperforms DeepSeek-R1 in LiveBench, the "most difficult LLMs list" led by Meta's Chief Scientist Likun Yang, IFEval, a set of instruction-following ability tests proposed by Google and others, and BFCL, a test to evaluate the accuracy of calling functions or tools proposed by the University of California, Berkeley and others.
AliCloud says this is Qwen's first step in large-scale reinforcement learning (RL) for enhanced reasoning. Through this journey, not only have we witnessed the great potential of scaling RL, but also recognized the untapped possibilities in pre-trained language models.
In working on the next generation of Qwen, Aliyun plans to bring it closer to realizing Artificial General Intelligence (AGI) by combining a more robust base model with RL that relies on scaled compute resources. Additionally, Aliyun is actively exploring the integration of intelligences with RL to enable long-duration reasoning, with the goal of unlocking higher intelligence through reasoning time scaling, so stay tuned.
