
February 24DeepSeek Open Source Week First Project FlashMLA Officially released.
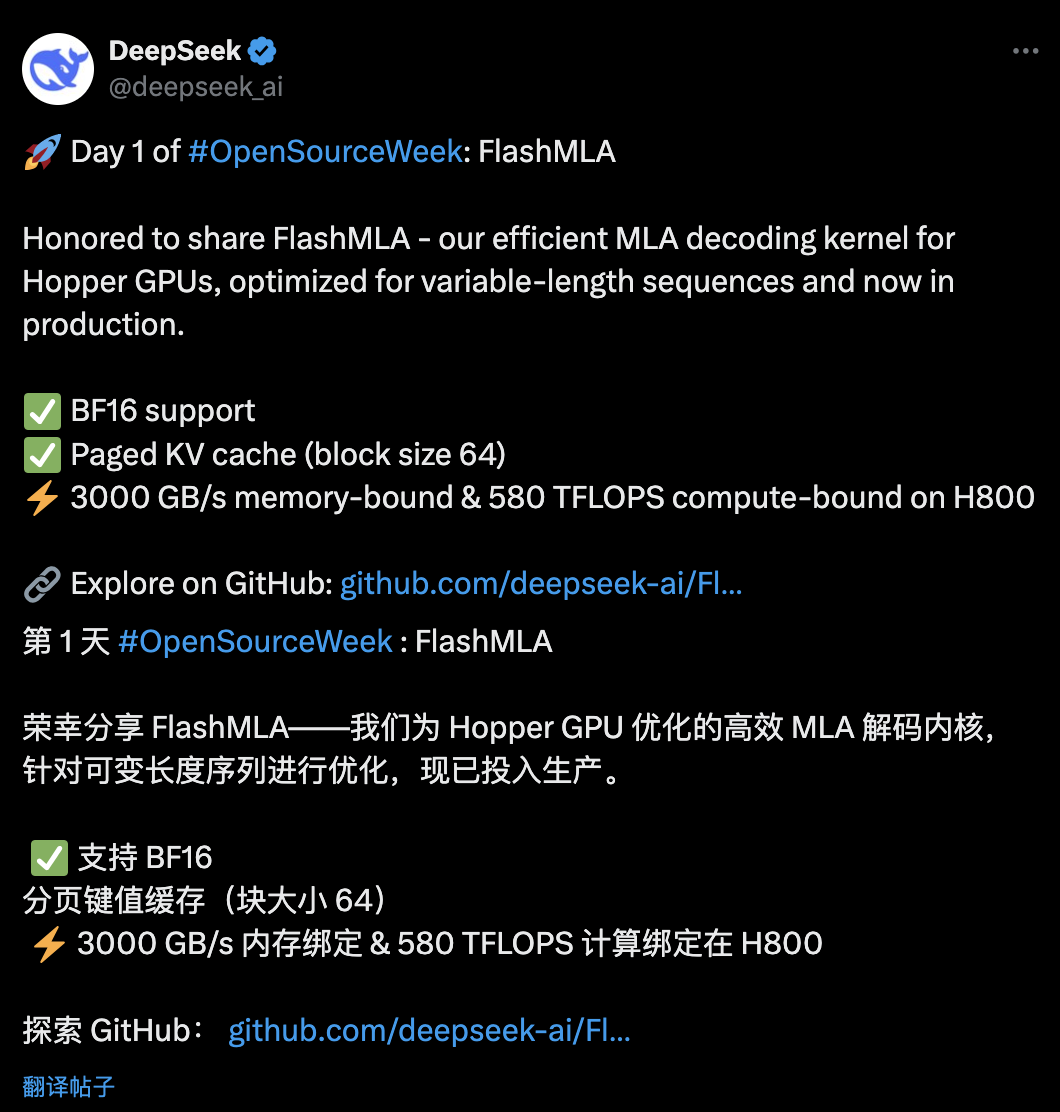
Officially, FlashMLA is inspired by FlashAttention 2&3 and the cutlass project. Specifically, FlashMLA is an efficient MLA (Multi-Head Latent Attention) decoding kernel optimized for Hopper GPUs with support for variable-length sequence processing, and is now in production use.
Optimized for multi-layer attention mechanisms, FlashMLA accelerates the decoding process of LLM to improve model responsiveness and throughput, which is especially important for real-time generative tasks (e.g., chatbots, text generation, etc.). In short, FlashMLA is an optimization that makes LLM models faster and more efficient on H800, especially for high-performance AI tasks.
Currently, the released version of FlashMLA supports the features of "BF16" and "Paged KV Cache, Block Size 64", which enables 3,000 GB/s of memory bandwidth and 580 TFLOPS of compute performance on the H800.
FlashMLA is now available on GitHub, and within 6 hours of its launch, it had more than 5,000 Star Favors and 188 Forks.
In addition, an investor focusing on AI hardware research said through Sina Technology that the FlashMLA released by DeepSeek is a major boon for domestic GPUs (graphics cards).
The investors analyzed that the previous domestic GPU performance is weak, now we can use the optimization ideas and methodology provided by FlashMLA to try to make the domestic GPU to greatly improve the performance, even if the architecture is different, the reasoning performance of the domestic graphics card will be a natural thing to improve later.
