
January 10, 2011 - Galaxy General announced yesterday (January 9) that it has united with the Beijing Zhiyuan Artificial Intelligence Research Institute (BAAI) and researchers from Peking University and the University of Hong Kong to release the first fully generalized end-to-end embodied grasping fundamental big model GraspVLA.
Note:"embodied intelligence"It refers to the integration of artificial intelligence into physical entities such as robots, giving them the ability to perceive, learn and interact dynamically with their environment.
According to the introduction, the training of GraspVLA contains two parts: pre-training and post-training. The pre-training is based entirely on synthetic big data, and the training data reaches the largest data volume ever -- the One billion frames of "visual-verbal-action" vs., mastering generalized closed-loop grasping capabilities, reaching base models.
After pre-training, the model can be directly Sim2Real (note: from simulation to reality) on unseen, ever-changing real scenes and objects with zero samples to test, which is officially claimed to meet the needs of most products; for special needs, post-training can be migrated from basic capabilities to specific scenarios with only small samples of learning, to maintain a high degree of generalization while forming professional skills that meet the needs of the product.
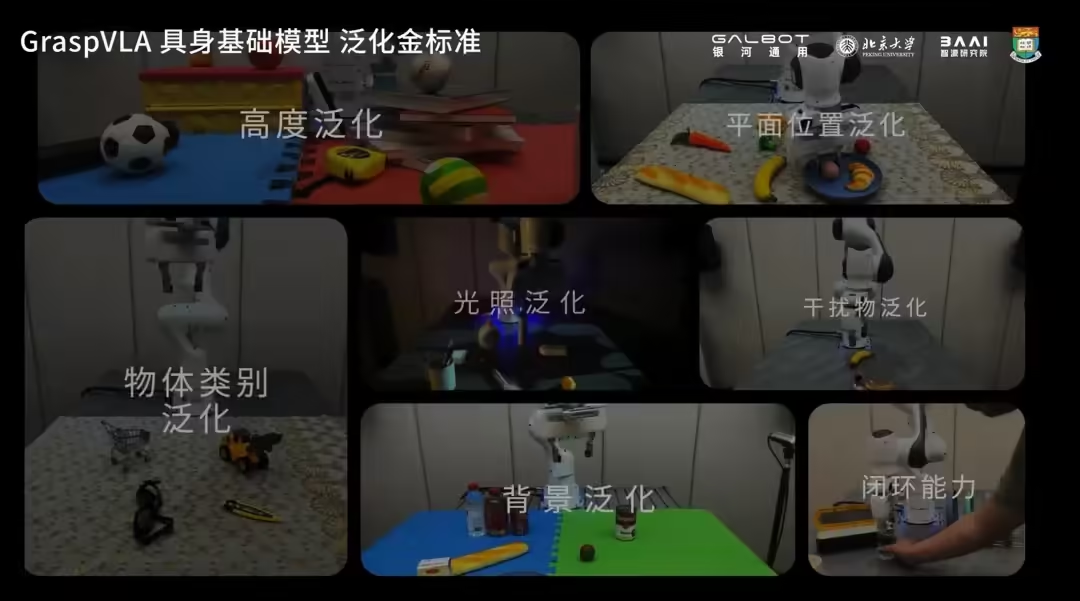
Officially announced the seven generalization "gold standards" that VLA needs to meet to reach the basic model: lighting generalization, background generalization, plane position generalization, spatial height generalization, action strategy generalization, dynamic interference generalization, and object category generalization.
