
MicrosoftRecently, a dedicatedLarge Language ModelThe tool library provides a series of tools, including creating different types of prompts, loading datasets and models, and performing adversarial prompt attacks, to support researchers in evaluating and analyzing LLMs from different aspects.
Project address:https://github.com/microsoft/promptbench
Paper address: https://arxiv.org/abs/2312.07910
Key features and capabilities of PromptBench include:
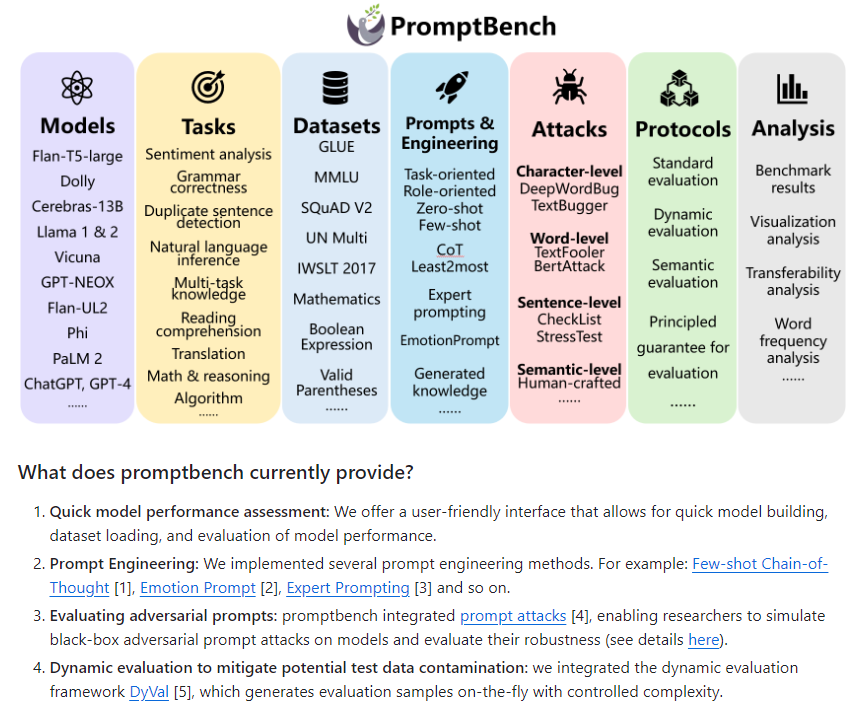
It supports multiple models and tasks, and can evaluate a variety of different large language models, such as GPT-4, as well as multiple tasks, such as sentiment analysis, grammar checking, etc.
At the same time, different evaluation methods such as standard evaluation, dynamic evaluation and semantic evaluation are provided to comprehensively test the performance of the model. In addition, a variety of prompt engineering methods are implemented, such as thought chains of a small number of samples, emotional prompts, expert prompts, etc. A variety of adversarial testing methods are also integrated to detect the model's response and resistance to malicious input.
It also includes analytical tools for interpreting evaluation results, such as visual analysis and word frequency analysis. Most importantly, PromptBench provides an interface that allows you to quickly build models, load datasets, and evaluate model performance. It can be installed and used with simple commands, making it easy for researchers to build and run evaluation pipelines.
PromptBench supports a variety of data sets and models, including GLUE, MMLU, SQuAD V2, IWSLT2017, etc., and supports many models such as GPT-4, ChatGPT, etc. This series of features and functions makes PromptBench a very powerful and comprehensive evaluation tool library.