
Meta issued a press release last week announcing the officialOpen SourceThe MobileLLM family of small language models that run on smartphones, and the addition of three new parameterized versions of the family, 600M, 1B, and 1.5B, are available on the project's GitHub project page (click here to visit).
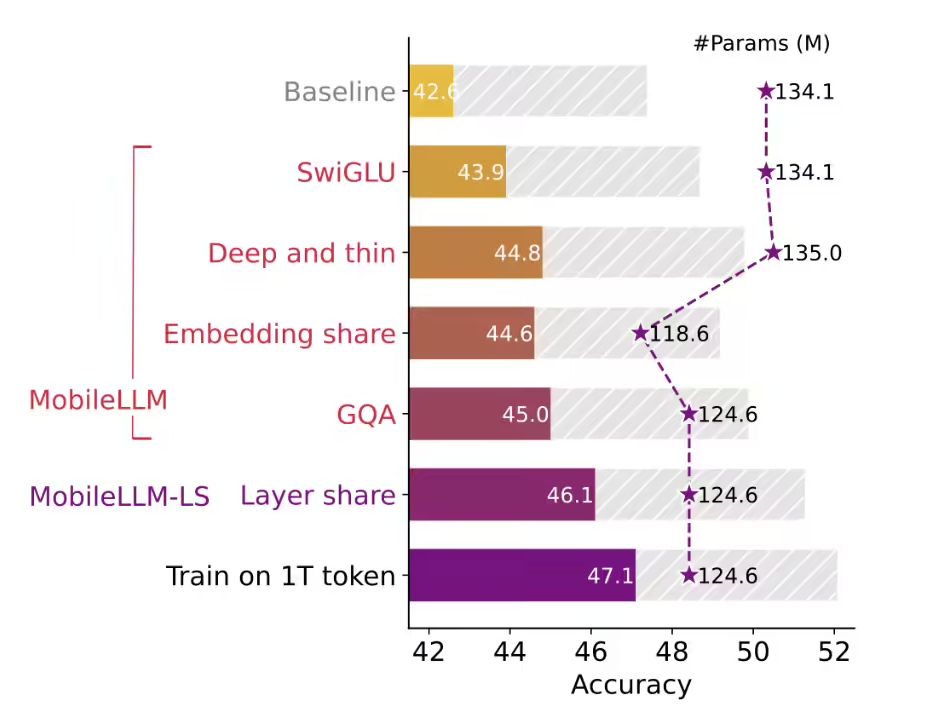
According to Meta researchers, the MobileLLM family of models, built specifically for smartphones, is claimed to have a streamlined architecture and introduces a "SwiGLU activation function," "grouped-query attention," and a "grouped-query attention" mechanism to balance efficiency and performance outcomes. The model family is designed for smartphones and claims to use a streamlined architecture and introduces the "SwiGLU activation function" and "grouped-query attention" mechanism, which can balance efficiency and performance results.
Additionally, MobileLLM models are claimed to be faster to train, with Meta researchers claiming that when they trained MobileLLM models with varying number of covariates on 1 trillion words (tokens) in a server environment with 32 Nvidia A100 80G GPUs, theyThe 1.5B version takes only 18 days and the 125M version takes only 3 days..
And from the results, the MobileLLM 125M and 350M models are 2.7% and 4.3% more accurate than the State of the Art (SOTA) models such as Cerebras, OPT, and BLOOM, respectively, in the zero-sample general knowledge comprehension task.
The Meta researchers also compared MobileLLM-1.5B to other models in the industry with larger parameter counts, and claimed to be ahead of models such as GPT-neo-2.7B, OPT-2.7B, BLOOM-3B, and Qwen 1.5-1.8B in terms of outcome testing.
