
Googleup to datePublishedGemini Pro has attracted much attention since its release, and Google claims that it is superior toGPT-3.5However, CMU's research demonstrated the comprehensive advantages of GPT-3.5 in multiple tasks through in-depth experimental comparisons. Although Gemini Pro is slightly inferior in some tasks, its overall performance is similar to GPT-3.5, adding new sparks to the competition in the large model field.
Paper address: https://arxiv.org/pdf/2312.11444.pdf
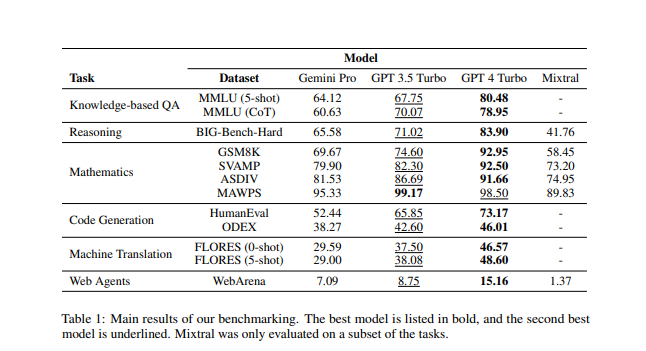
The research involved knowledge-based question answering, general reasoning, mathematical problems, code generation and other fields. In the knowledge-based question answering task, Gemini Pro lags behind GPT-3.5 in some subtasks, especially in the output of multiple-choice answers. In the general reasoning test, Gemini Pro's accuracy is slightly lower than GPT-3.5Turbo, especially when dealing with longer and more complex questions, while GPT-4Turbo performs more robustly.
Tests in the area of math problems include elementary school math benchmarks, robust reasoning, different language patterns, and problem types. Gemini Pro is slightly lacking in some tasks, especially in diverse language pattern tasks, where it performs slightly worse than GPT-3.5Turbo. In terms of code generation, Gemini Pro performs worse than GPT-3.5Turbo in both tasks, and the gap is even greater than that of GPT-4Turbo.
Overall, Gemini Pro, as a multimodal model, performs well in specific areas, surpassing GPT-3.5, although it is slightly insufficient in some tasks. However, in most tests, GPT-3.5Turbo still maintains its leading position, proving its superior performance among open source models. This research provides an objective and neutral third-party comparison for large model competition in the field of science and technology, and provides a useful reference for future model development.
