
Alibaba CloudThe latest release is a large-scale audio language model called Qwen-Audio. The model can accept a variety of audio signal inputs and can perform audio analysis or directly answer voice commands, greatly improvingVoice InteractionExperience.
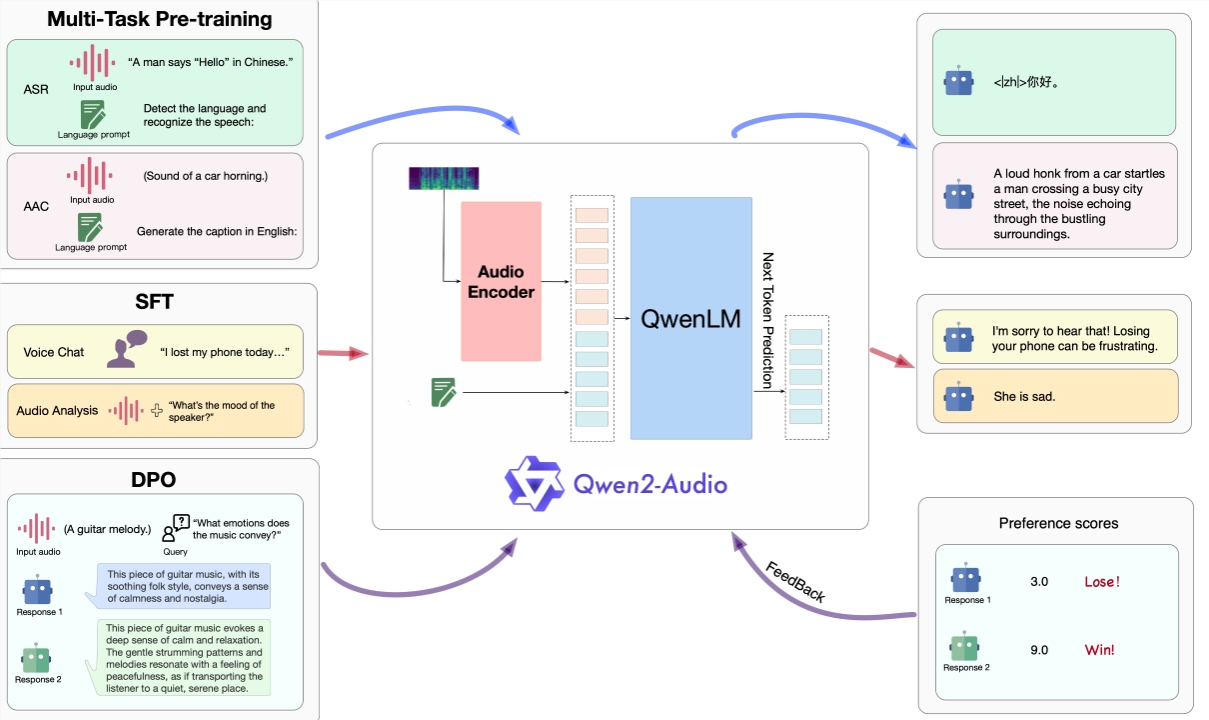
In this release, Qwen2udio provides two unique audio interaction modes: audio chat and audio analysis. Users can communicate with others without typing any text. Qwen2-Audio It can conduct voice exchanges and provide audio and text commands for analysis during the interaction to bring users a more convenient experience.
Qwen2-Audio can intelligently understand the content in the audio and respond appropriately to voice commands. For example, in an audio segment that contains sounds, multi-speaker conversations, and voice commands at the same time, Qwen2-Audio can directly understand the command and provide an interpretation and response to the audio.
In addition, DPO also optimizes the model's performance in terms of factuality and compliance with expected behavior. According to the evaluation results of AIR-Bench, Qwen2-Audio outperforms previous SOTAs such as Gemini-1.5-pro in tests focusing on audio-centric instruction tracking functions. Qwen2-Audio is open source and aims to promote the advancement of the multimodal language community.
It is understood that the Qwen2-Audio series will launch two models: Qwen2-Audio and Qwen-Audio-Chat, providing users with a richer audio interaction experience.
The researchers will conduct a comprehensive evaluation of the Qwen2-Audio model, assessing its performance on a variety of tasks without any task-specific fine-tuning. In terms of English automatic speech recognition (ASR) results, Qwen2-Audio showed higher performance compared to previous multi-task learning models.

In terms of Qwen2-Audio's chat capabilities, researchers measured its performance on the AIR-Bench chat benchmark (Yang et al., 2024), and Qwen2-Audio demonstrated state-of-the-art (SOTA) instruction tracking capabilities across speech, sound music, and mixed audio subsets. It shows substantial improvements over Qwen-Audio and significantly outperforms other LALMs.
