
Recently, a study calledHyperHumanA new AI framework from the University of California, Berkeley, has been unveiled, ushering in a new era for generating ultra-realistic human images. The key breakthrough of this framework is that it combines structured diffusion technology to successfully overcome the challenges faced by previous models in generating human images.
Users do not need professional skills, they only need to provide conditions such as text and pose, and HyperHuman can generate highly realistic human images from them. This has far-reaching significance for a variety of applications such as image animation and virtual try-on. Previous methods either rely on variational autoencoders (VAEs) in a reconstruction manner or improve realism through generative adversarial networks (GANs). However, these methods are often only applicable to small-scale datasets due to unstable training and limited model capacity, resulting in a lack of diversity in the generated images.
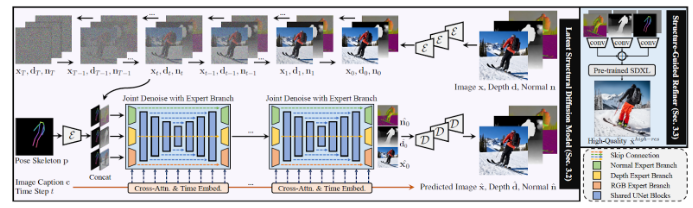
The HyperHuman framework introduces structural diffusion models (DMs), which have become the dominant architecture in generative AI. Although previous text-to-image models (T2I) still face challenges when using structural diffusion, HyperHuman successfully solves the problem of non-rigid deformation of human form through the combination of Latent Structural Diffusion Model and Structure-Guided Refiner. These two modules work together to collaboratively model the appearance, spatial relationships, and geometry of the image in a unified network.
The key to HyperHuman is to recognize that human images have structural properties at multiple levels, from coarse-grained body skeletons to fine-grained spatial geometry. To achieve this, the researchers built a large-scale human-centric dataset called HumanVerse, which contains 340 million wild human images with detailed annotations. Based on this dataset, HyperHuman designed two key modules, namely Latent Structural Diffusion Model and Structure-Guided Refiner. The former ensures the spatial alignment of texture and structure by enhancing the pre-trained diffusion backbone and denoising RGB, depth, and normals. The latter provides prediction conditions for detailed and high-resolution image generation through spatially aligned structural maps.

In addition, HyperHuman also adopts a powerful modulation scheme to mitigate the impact of error accumulation in the two-stage generation process. Through a carefully designed noise plan, low-frequency information leakage is eliminated, ensuring the uniformity of local area depth and surface normal values. Each branch uses the same time step to enhance learning, which promotes feature fusion. This whole set of designs ensures that the model treats structural and texture richness in a unified manner.
Comparisons with the current state of the art show that HyperHuman exhibits superior quality in the generated images.FirstThe input skeleton, jointly denoised normals, depth, and coarse RGB (512×512) computed by HyperHuman are shown in a 4×4 grid.
The emergence of HyperHuman provides a new method for generating ultra-realistic human images, breaking through the limitations of previous models and bringing broader possibilities for future applications such as virtual try-on and image animation.
Project URL: https://snap-research.github.io/HyperHuman/
Paper URL: https://arxiv.org/abs/2310.08579
