
Yesterday,Dark Side of the MoonUnderKimi The open platform announced that Context Caching has entered public beta. This technology can reduce the cost of using long text flagship models of up to 90% for developers without changing the API price, and significantly improve the response speed of the model.
Context Caching is an efficient data management technology that allows the system to pre-store large amounts of data or information that may be frequently requested. In this way, when you request the same information again, the system can quickly provide it directly from the cache without recalculating or retrieving it from the original data source, saving time and resources. Context Caching is particularly suitable for scenarios with frequent requests and repeated references to a large amount of initial context, which can significantly reduce the cost of long text models and improve efficiency!
Specifically, "context caching" can be applied to scenarios with frequent requests and repeated references to a large number of initial contexts, bringing the following two effects:
Cost reduction of up to 90%: For example, in scenarios where a large number of questions need to be asked about fixed documents, context caching can save a lot of costs. For example, for a hardware product manual of about 90,000 words, pre-sales support personnel need to conduct multiple intensive questions and answers in a short period of time. After access to context caching, the cost can be reduced to about 10%.
The first token delay is reduced by 83%: For a request of a 128k model, it usually takes 30 seconds to return the first token. Through context caching, the first token delay can be reduced to 5 seconds on average, reducing the delay time by about 83%.
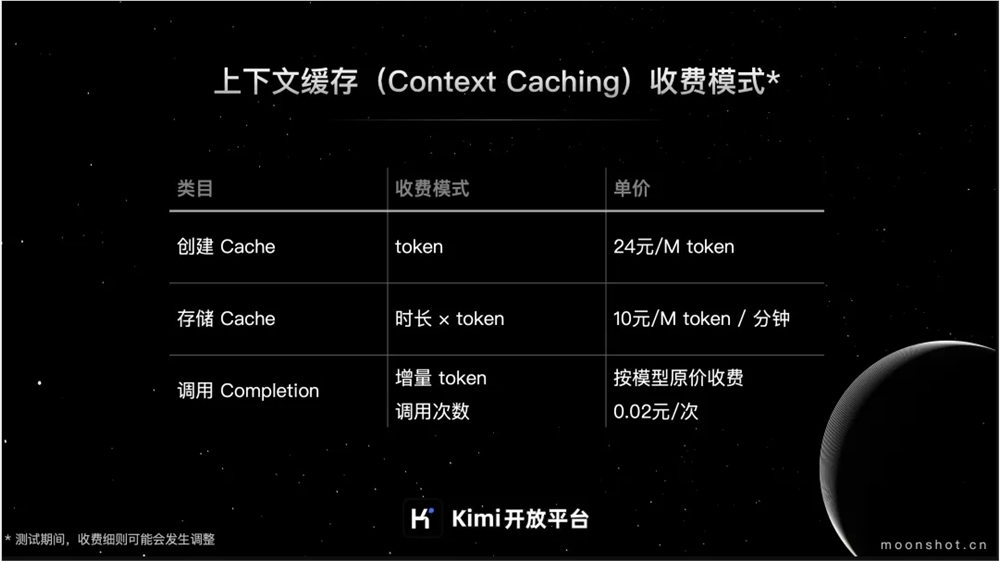
The charging model of Context Caching is mainly divided into the following three parts:
Cache creation cost:
Call the Cache creation API. After successfully creating the Cache, the actual amount of tokens in the Cache will be charged. 24 yuan/M token
Cache storage fee:
During the cache lifespan, the cache storage fee is charged per minute. 10 yuan/M token/minute
Cache call fee:
Charges for calling incremental tokens for Cache: charged according to the original price of the model
Cache call charges:
During the cache survival time, if the user requests a successfully created cache through the chat interface, and the chat message content successfully matches the surviving cache, the cache call fee will be charged according to the number of calls. 0.02 yuan/time