
ByteDanceReleased the new generation of Depth Anything V2Deep Model, the model has achieved significant performance improvements in the field of monocular depth estimation. Compared with the previous generation Depth Anything V1, the V2 version has finer details and stronger robustness, while also significantly improving efficiency, more than 10 times faster than the Stable Diffusion-based model.
Key Features:
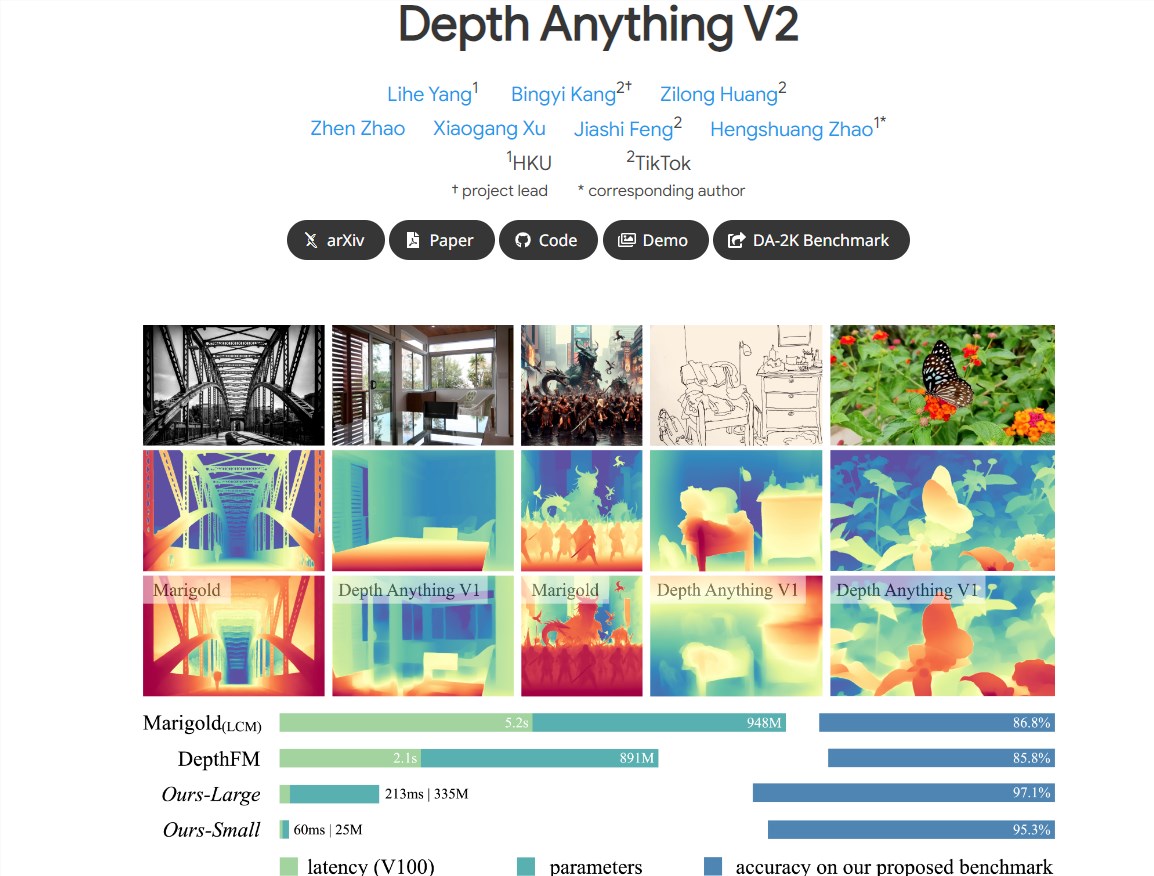
Finer details: The V2 model is optimized on details, providing finer depth predictions.
High Efficiency and Accuracy: Compared with the model built on SD, V2 has significant improvements in efficiency and accuracy.
Multi-scale model support: Models of different scales are provided, with parameters ranging from 25M to 1.3B, to adapt to different application scenarios.
Key Practices: The performance of the model is improved by replacing real images with synthetic images, expanding the capacity of the teacher model, and using large-scale pseudo-annotated images to teach the student model.
Three key practices to improve model performance:
Use of synthetic images: All annotated real images are replaced with synthetic images to improve the training efficiency of the model.
Teacher model capacity expansion: By expanding the capacity of the teacher model, the generalization ability of the model is enhanced.
Application of pseudo-annotated images: Using large-scale pseudo-annotated real images as a bridge to teach the student model improves the robustness of the model.
Support for a wide range of application scenarios:
To meet the needs of a wide range of applications, researchers provide models of different sizes and exploit their generalization capabilities by fine-tuning them with metric deep labels.
A diverse evaluation benchmark with sparse depth annotations is constructed to facilitate future research.
Training methods based on synthetic and real images:
The researchers first trained a maximum teacher model on synthetic images, then generated high-quality pseudo-labels for large-scale unlabeled real images and trained a student model on these pseudo-labeled real images.
The training process used 595K synthetic images and 62M+ real pseudo-labeled images.
The launch of the Depth Anything V2 model demonstrates ByteDance's innovative capabilities in the field of deep learning technology. Its efficient and accurate performance characteristics indicate that the model has broad application potential in the field of computer vision.
Project address: https://depth-anything-v2.github.io/
