Official Website: https://ollama.com/
Github:https://github.com/ollama/ollama
Ollama is aOpen SourcePlatform for managing and running various large language models (LLMs), such as Llama3, gemma and qwen.
It provides a command line interface (CLI) for installation, model management, and interaction.
You can use Ollama to download, load, and run different LLM models based on your needs.
# Windows Installation
Requirements: Windows 10 or above operating system
Installation package download address: https://ollama.com/download/windows
Download the corresponding system installation package
After the download is complete, double-click the downloaded installer
Click Install to install
After the installation is complete, open a terminal and enter the following command in the terminal to run a large language model for testing. Here we take Qianwen, which performs relatively well in Chinese, as an example:
ollama run qwen
The model will be downloaded first when it is run for the first time. After the download is complete, you can ask questions
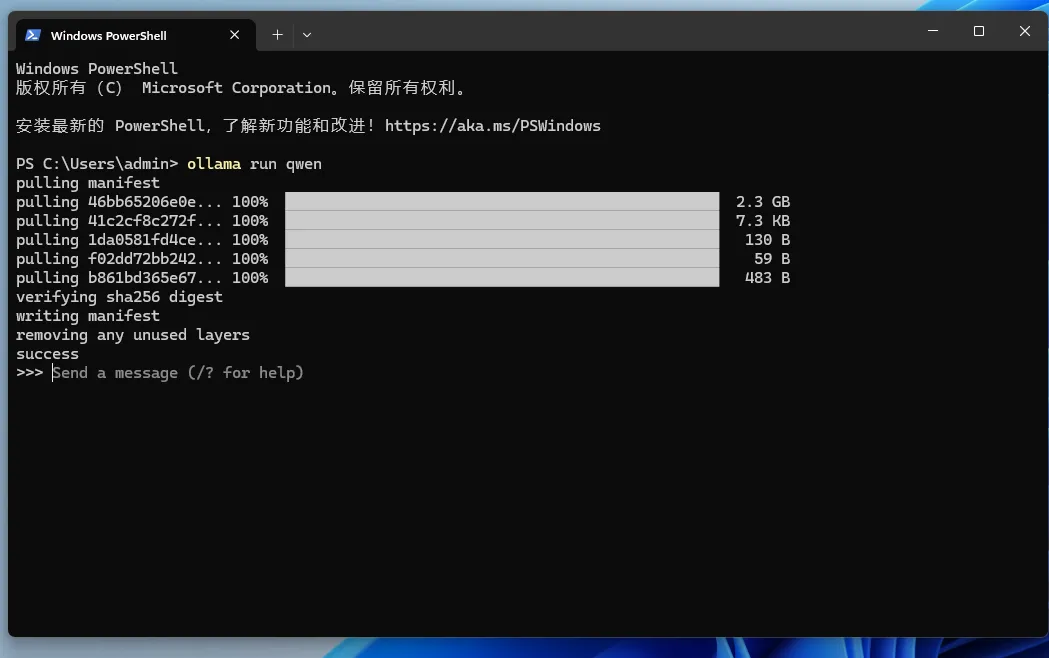
Once the model is downloaded, we can use it by entering questions in the terminal:
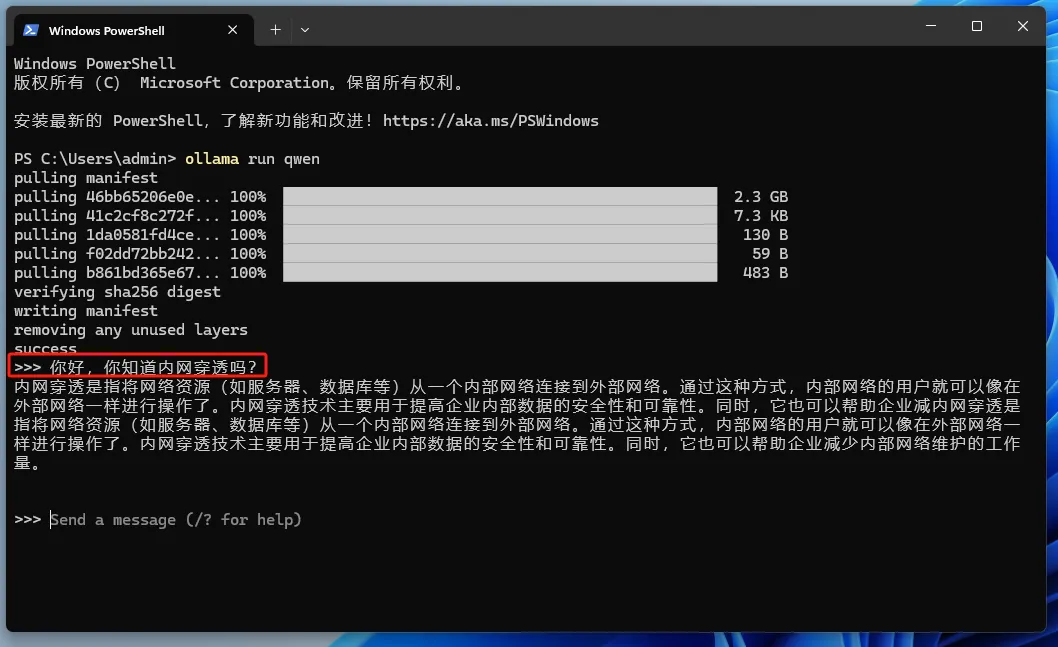
So far, we ordinary people can also use AILarge ModelQuestion and answer session!!!
#Docker installation
①Docker deployment
# Only CPU uses this docker run -itd --name ollama -v ollama:/root/.ollama -p 11434:11434 ollama/ollama # There is a GPU and use this docker run -itd --name ollama --restart always --gpus=all -v /home/suxy/ollama:/root/.ollama -p 11434:11434 ollama/ollama
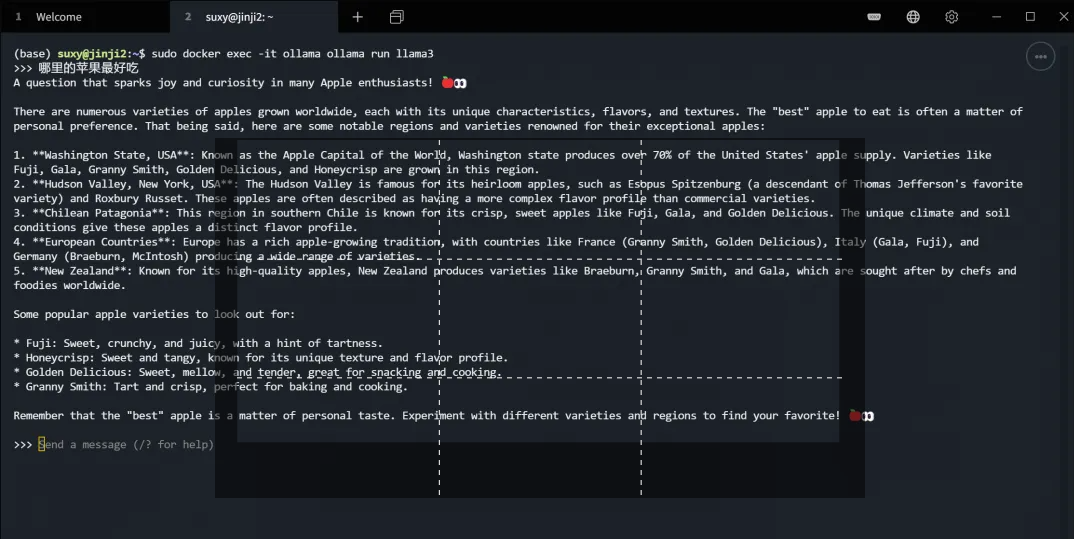
② Pull the model and run it
# Qianwen 4b docker exec -it ollama ollama run qwen #llama3 docker exec -it ollama ollama run llama3 #gemma docker exec -it ollama ollama run gemma
When you pull a model for the first time, you will first download the model. After the model is downloaded, you can start a conversation. The example is as follows:
③Other models
You can view:https://ollama.ai/library
You can also download models with different parameter levels according to your needs.
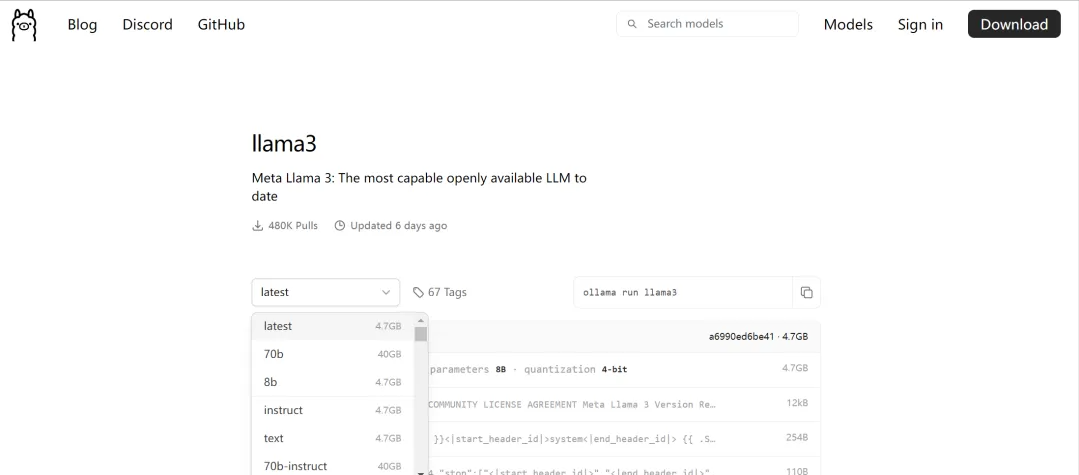
Open WebUI
The above can only be used in the terminal, and the operation interface is not as beautiful as ChatGPT. If you can use the web page to interact, the user experience will be better, and you can also keep the previous chat records and look through them for inquiries.
In this case, deploying the Open WebUI project can implement an interactive interface similar to chatgpt.
This tutorial takes the Open WebUI project as an example. It was formerly known as Formerly Ollama WebUI and is specifically adapted for Ollama's WebUI.
Official documentation: https://docs.openwebui.com/getting-started/
Github: https://github.com/open-webui/open-webui
#docker quick deployment
Execute the following command
The # example uses ollama-webui docker run -itd --name ollama-webui --restart always -p 3500:8080 --add-host=host.docker.internal:host-gateway ghcr.io/ollama-webui/ ollama-webui:latest # or docker run -itd --name open-webui --restart always -p 3500:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/ backend/data ghcr.io/open-webui/open-webui:latest
After successful deployment, the browser opens the connection:http://127.0.0.1:3500
First time login, create an account first
Click sign up to register, and remember your account, email address, and password. You will need to use your email address and password to log in next time:
Then click create account to create an account, and then you can use the Open WebUI similar to the chatgpt interface in the browser!
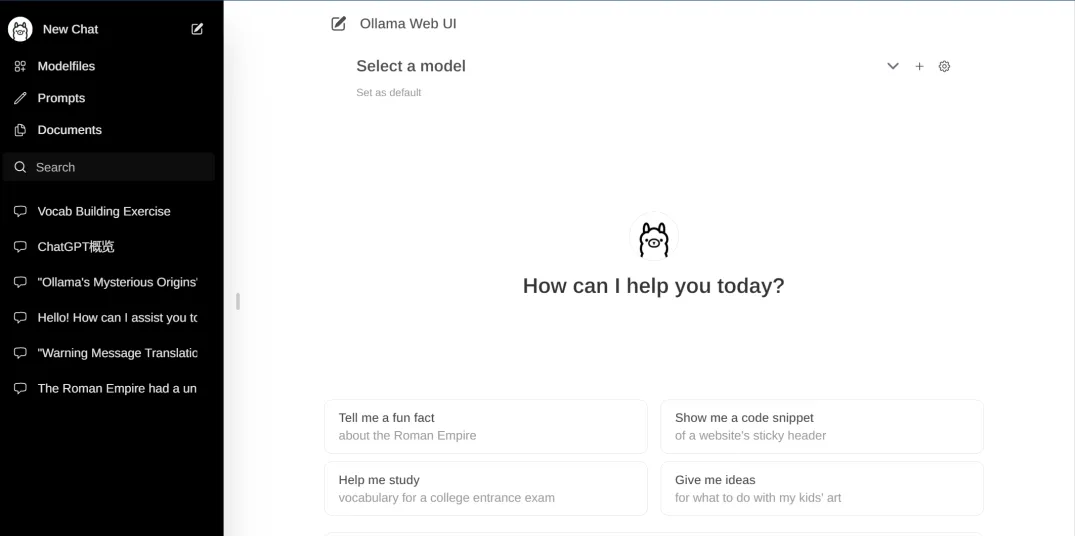
Add and click on the settings in the upper right corner to set the ollama service installed above, for example:http://localhost:11434/api
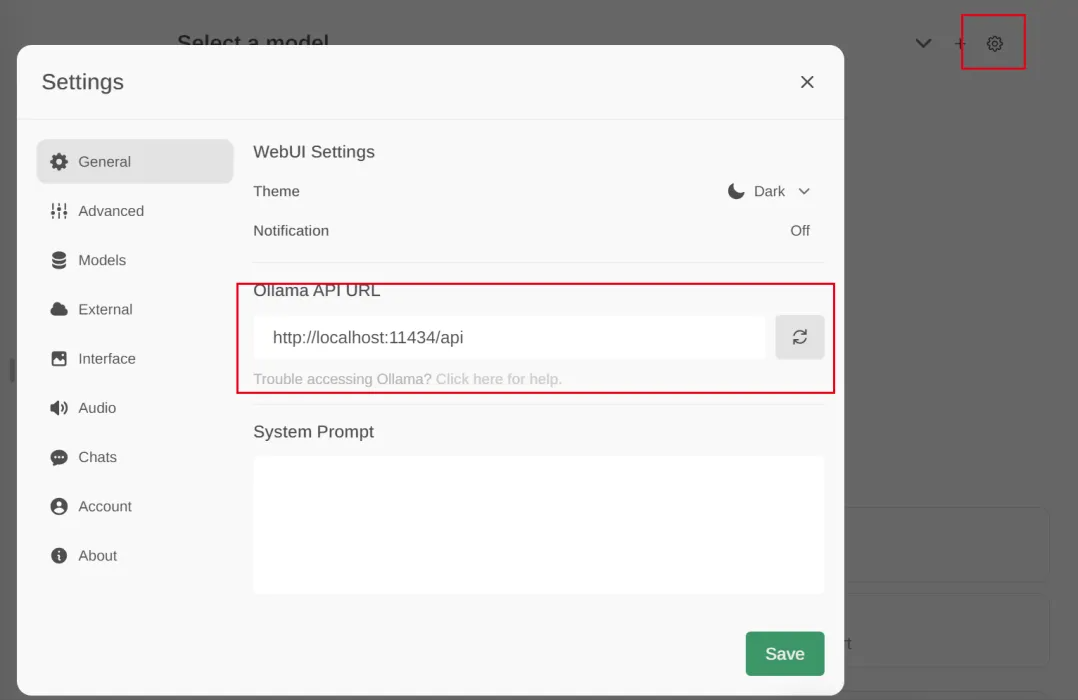
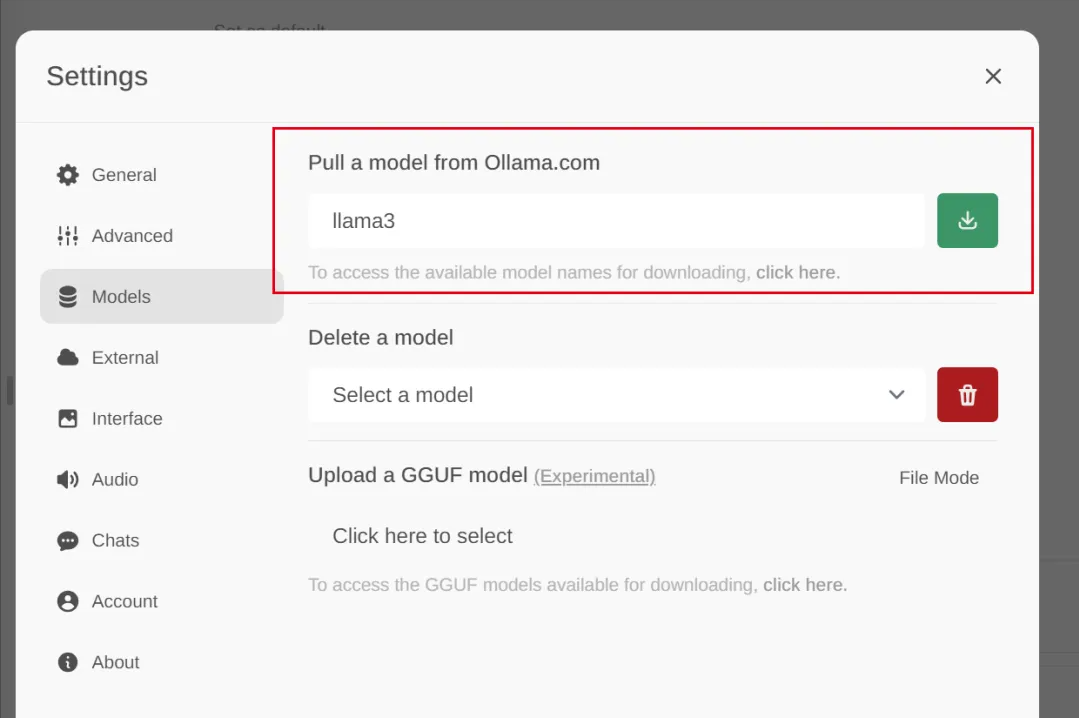
At the same time, you can download the model you want to install on the page. After clicking the download button, you can see the download progress
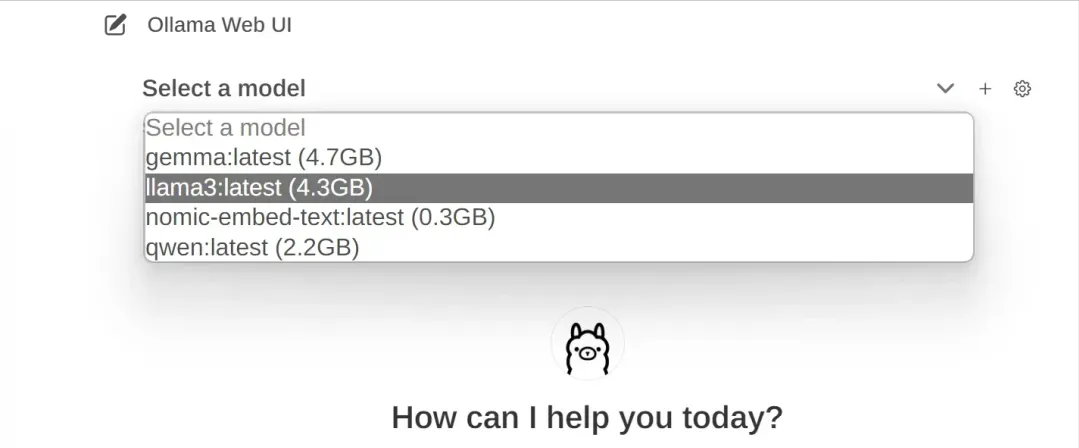
Click select a model to select which installed model to use
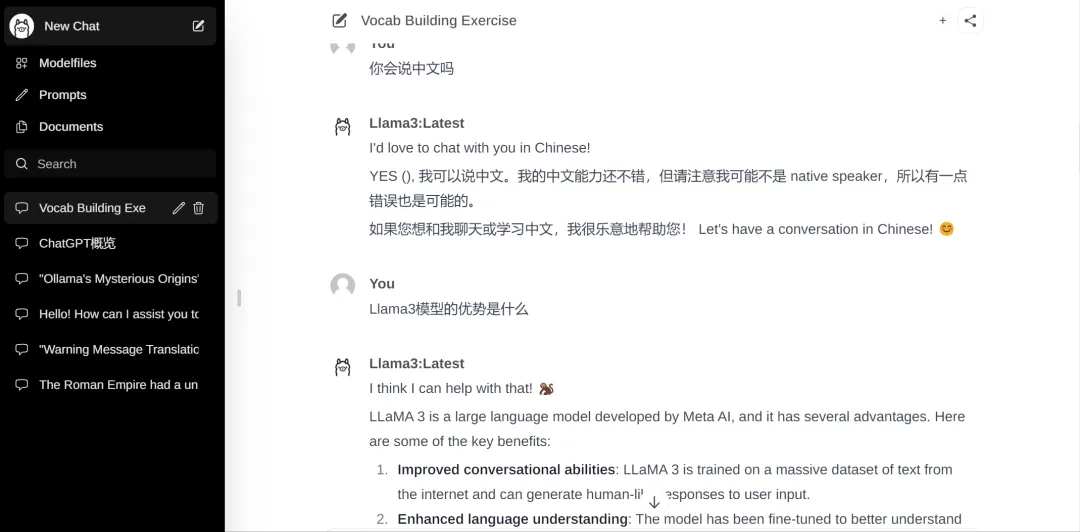
Next, you can chat happily with AI!
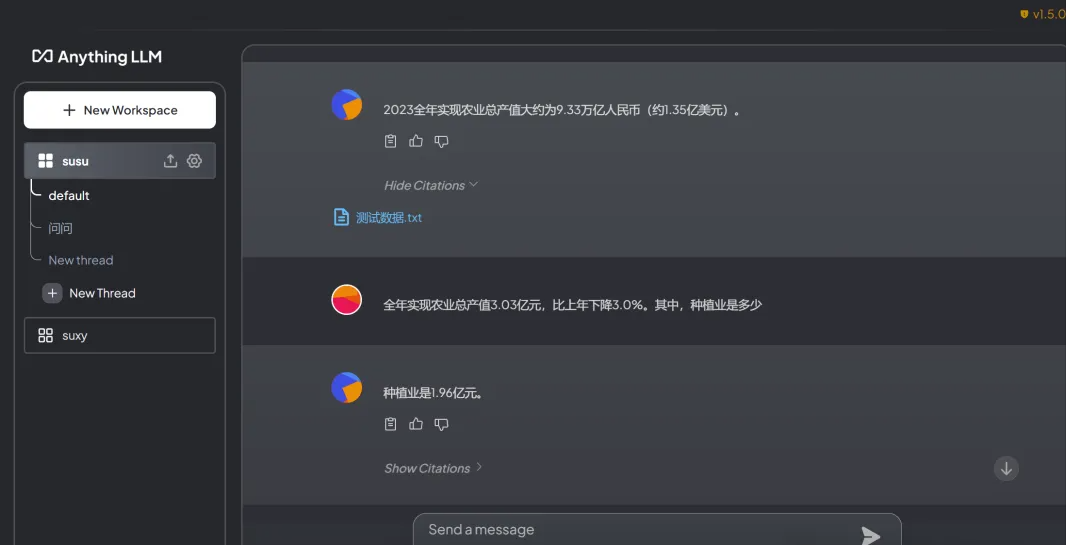
AnythingLLM
Official documentation: https://docs.useanything.com/
Github: https://github.com/Mintplex-Labs/anything-llm
AnythingLLM is an open source, efficient, and customizable private knowledge base solution built on the RAG (Retrieval-Augmented Generation) solution. You can use commercial off-the-shelf LLM or popular open source LLM and vectorDB solutions to build private ChatGPT
# download and install AnythingLLM
Official installation tutorial: https://docs.useanything.com/anythingllm-desktop/windows-instructions
Installation package download address: https://useanything.com/download
This example takes Windows as an example:
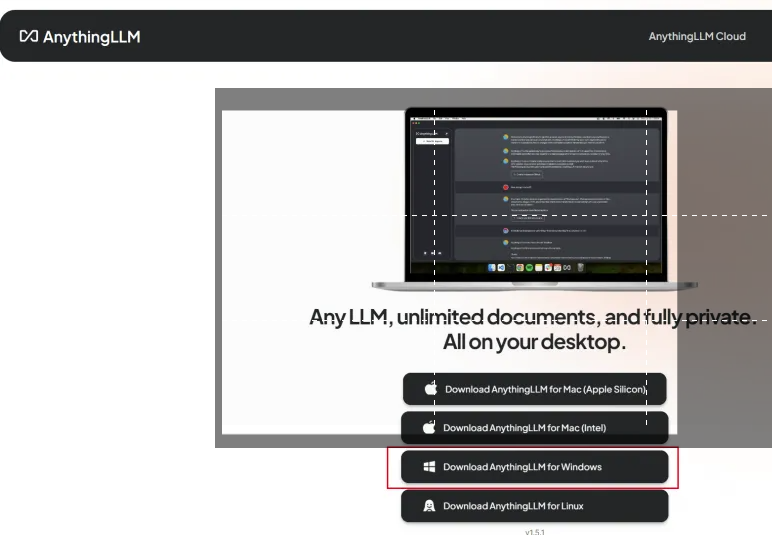
After the installation package is downloaded, double-click the installation package to install it.
Because I have already configured it, it is difficult to take a screenshot of the initial configuration interface, but you can find it in the settings
# configuration LLM
AnythingLLM supports LLMs such as OpenAI, LocalAi, Ollama, etc.
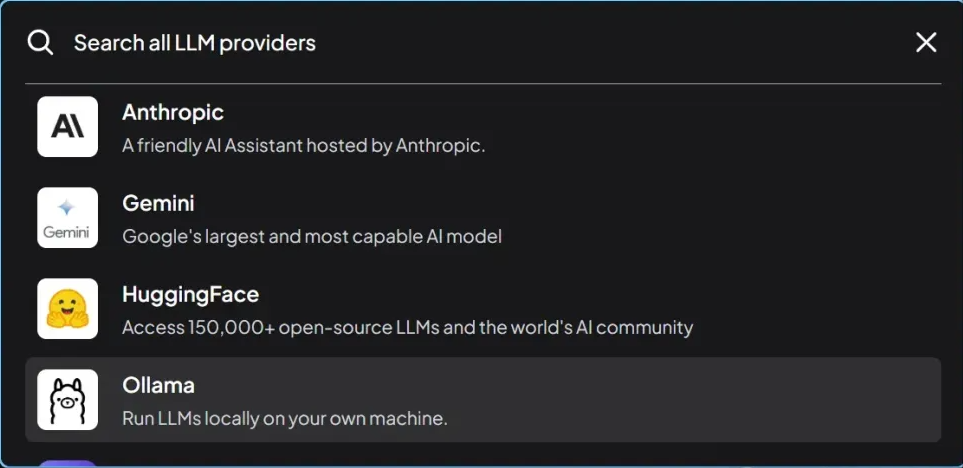
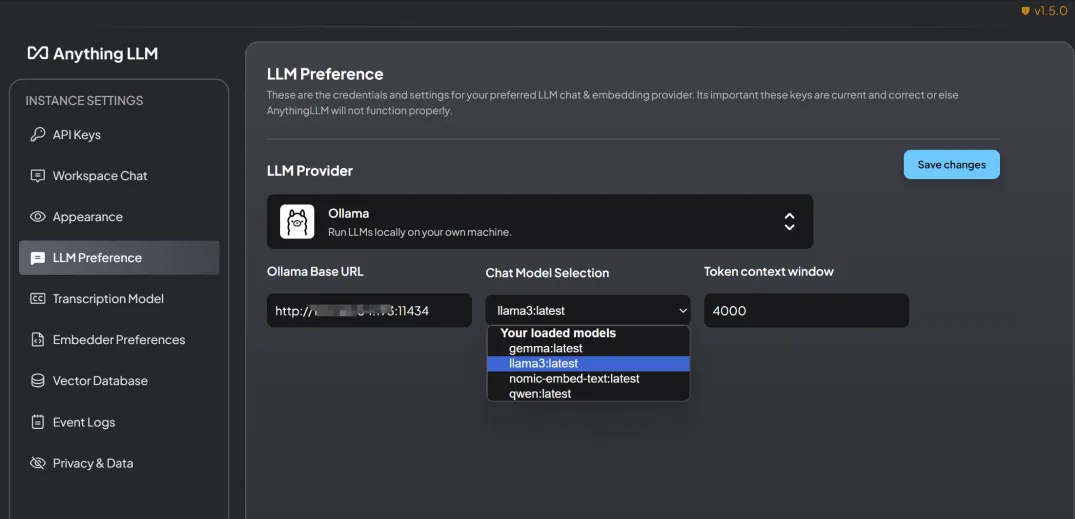
Select Ollama as the background service here, and fill in the URL herehttp://127.0.0.1:11434, which is the service port started by Ollama above. After filling in the LLM model, select llama3
# configuration Embedding Model
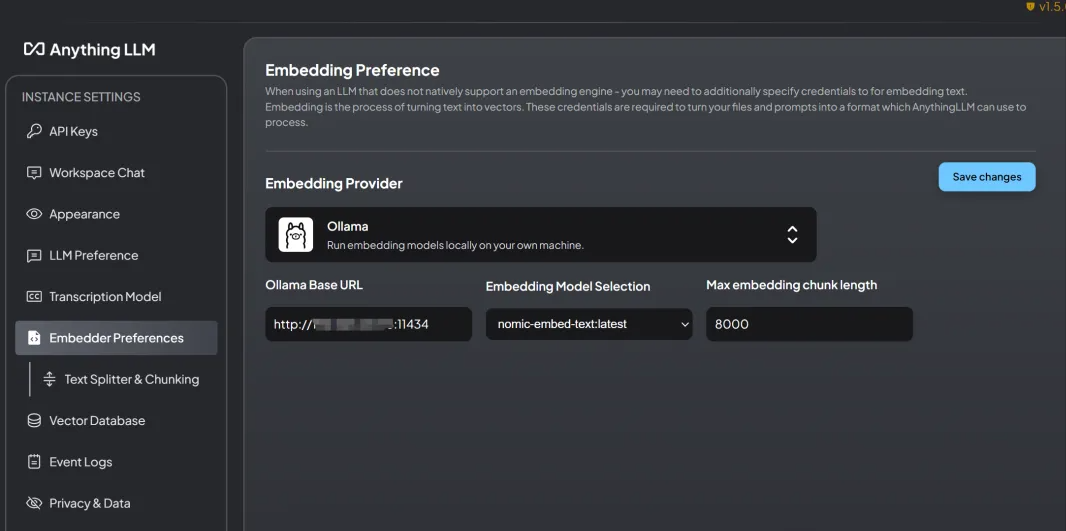
The Embedding Models supported by AnythingLLM include: AnythingLLM Native Embedder (default), OpenAi, LocalAi, Ollama, etc.
Here we also select Ollama as the background service and fill in the URL herehttp://127.0.0.1:11434After filling in the Embedding Model, select nomic-embed-text:latest:
# Configure Vector Datebase
The vector databases supported by AnythingLLM are: LanceDB (default), Astra DB, Pinecone, Chroma, Weaviate, QDrant, Milvus, Zilliz, etc.
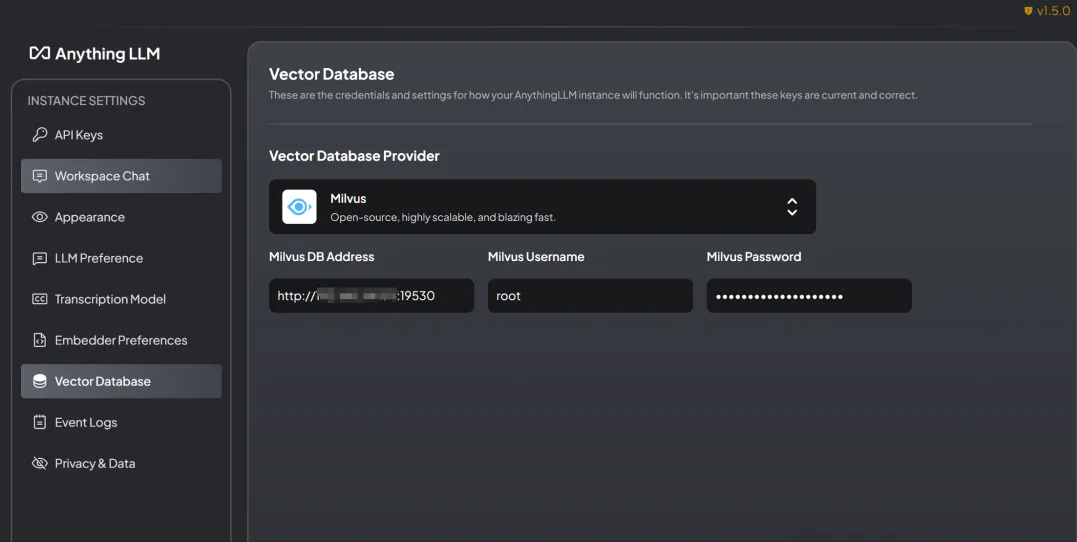
After completing the above three key configurations, you can start using AnythingLLM!!!
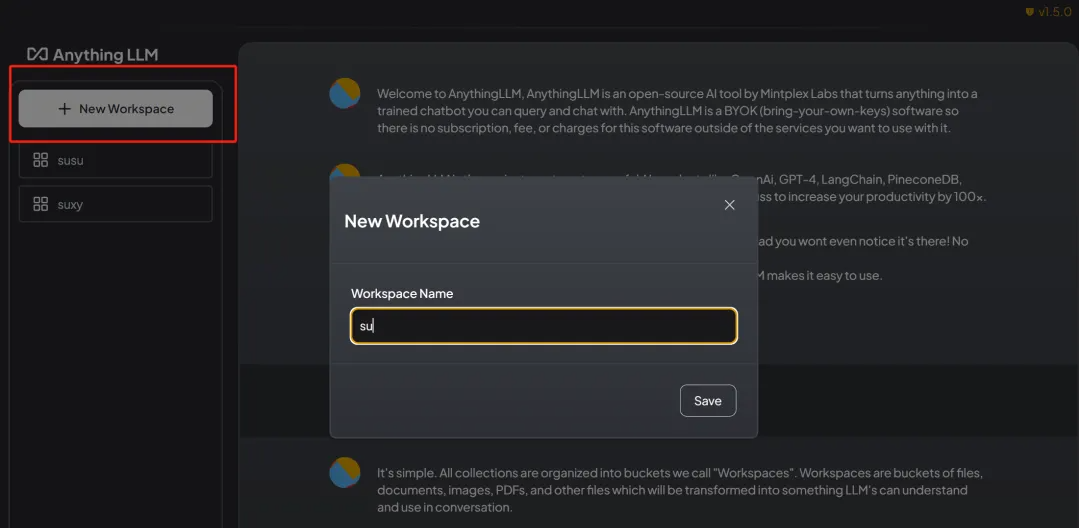
Click New Workspace to create a new document library and fill in the name
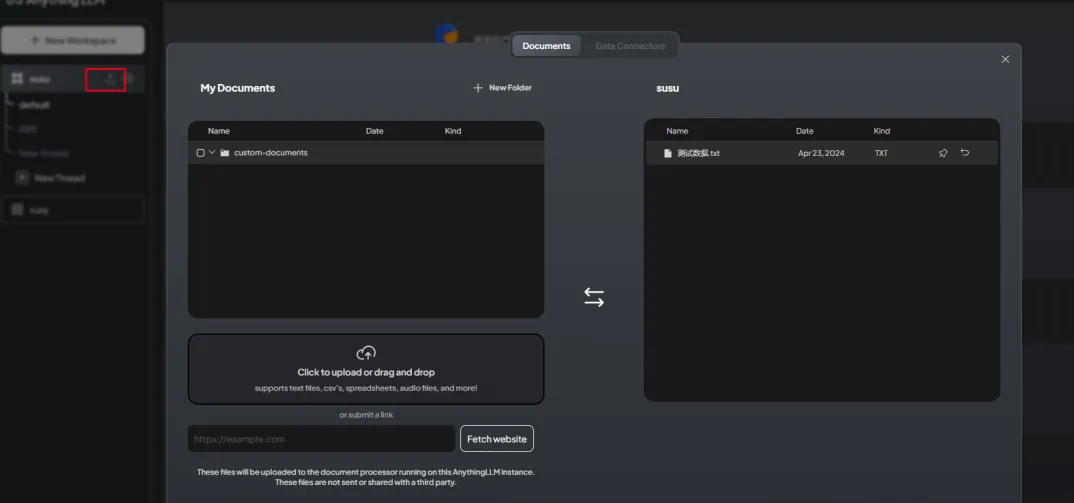
Click the Upload Files button to start adding documents:
Now you can ask questions based on the content of the document.