
New research published in the journal Nature shows that theGPT-4Performance in Theory of Mind (ToM) is comparable to humans and even exceeds them in some areas. The study was conducted by James W. A. Strachan et al. They evaluated the performance of GPT-4, GPT-3.5, Llama2, and human participants through a series of tests and compared them.
The following are the key findings of the study.
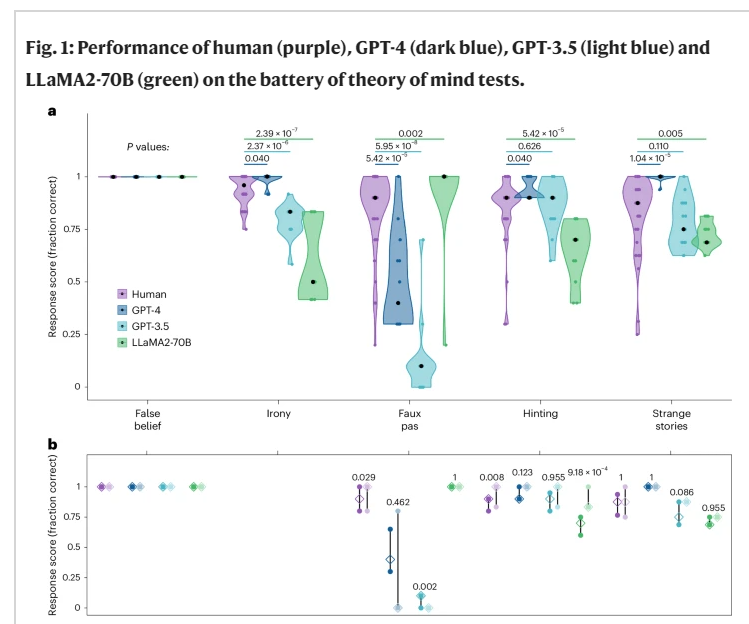
Theory of Mind Performance:Theory of Mind is the ability to understand the mental states of others and is critical to social interaction.The GPT-4 performs as well as humans in Theory of Mind and even outperforms humans in detecting sarcasm and innuendo.
Test Items:The study included five test items, namely false beliefs, irony, gaffes, innuendo, and strange stories.The GPT-4 significantly outperformed humans on three tests, namely irony, innuendo, and strange stories, and was on par with humans on the false beliefs test, and only underperformed humans on the gaffes test.
Conservatism:The GPT-4's low scores on the Gaffe Test are not due to a lack of comprehension, but rather to a conservative strategy that does not readily give definitive opinions.
Gaffe Likelihood Test:In the Gaffe Likelihood Test, the GPT-4 demonstrated flawless performance, showing that it was able to successfully infer the speaker's mental state and determine that an unintentional offense was more likely than an intentional insult.
Separation of ability and performance:Research suggests that GPT models may have the technical sophistication to compute mind-like inferences, but perform differently from humans under uncertainty. Humans tend to eliminate uncertainty, whereas GPTs do not spontaneously compute inferences to reduce uncertainty.
Cautious Behavior:GPT-4's conservatism in gaffe testing may stem from mitigating measures in its underlying architecture that are designed to improve factuality and avoid over-reliance on the model by users.
The results of this study suggest that the ability of the GPT-4 to understand human mental states may be underestimated. The researchers call for a "machine psychology" that uses the tools and paradigms of experimental psychology to systematically study the capabilities and limitations of large-scale language models.
Paper address:https://www.nature.com/articles/s41562-024-01882-z