
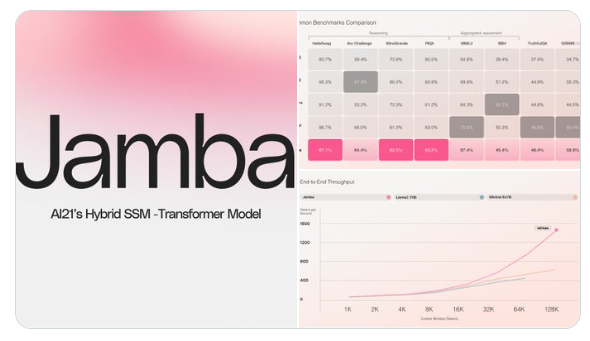
AI21发布了世界首个Mamba的生产级模型:Jamba。这个模型采用了开创性的SSM-Transformer架构,具有52B参数,其中12B在生成时处于活动状态。Jamba结合了Joint Attention和Mamba技术,支持256K上下文长度。单个A10080GB最多可容纳140K上下文。与Mixtral8x7B相比,长上下文的吞吐量提高了3倍。
模型地址:https://huggingface.co/ai21labs/Jamba-v0.1
Jamba代表了在模型设计上的一大创新。它结合了Mamba结构化状态空间(SSM)技术和传统的Transformer架构的元素,弥补了纯SSM模型固有的局限。Mamba是一种结构化状态空间模型(Structured State Space Model, SSM),这是一种用于捕捉和处理数据随时间变化的模型,特别适合处理序列数据,如文本或时间序列数据。SSM模型的一个关键优势是其能够高效地处理长序列数据,但它在处理复杂模式和依赖时可能不如其他模型强大。
而Transformer架构是近年来人工智能领域最为成功的模型之一,特别是在自然语言处理(NLP)任务中。它能够非常有效地处理和理解语言数据,捕捉长距离的依赖关系,但处理长序列数据时会遇到计算效率和内存消耗的问题。
Jamba模型将Mamba的SSM技术和Transformer架构的元素结合起来,旨在发挥两者的优势,同时克服它们各自的局限。通过这种结合,Jamba不仅能够高效处理长序列数据(这是Mamba的强项),还能保持对复杂语言模式和依赖关系的高度理解(这是Transformer的优势)。这意味着Jamba模型在处理需要理解大量文本和复杂依赖关系的任务时,既能保持高效率,又不会牺牲性能或精度。