
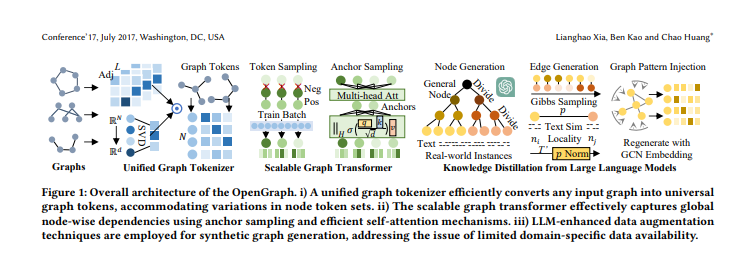
近期,香港大学发布了OpenGraph,这是一项突破性的成果,成功攻克了图基础模型领域的三大难题。该模型通过巧妙的技术实现了零样本学习,可以适配多种下游任务。OpenGraph的构建主要分为统一图Tokenizer、可扩展的图Transformer和大语言模型知识蒸馏三个部分。
OpenGraph通过创建统一的图Tokenizer解决了不同数据集之间节点集合和特征空间的变化问题。采用拓扑感知映射方案,实现了对不同图数据的高效tokenization,使得模型能够更好地理解和处理不同的图结构。
论文地址:https://arxiv.org/pdf/2403.01121.pdf
可扩展的图Transformer部分引入了采样技巧,包括Token序列采样和自注意力中的锚点采样方法。这些技巧有效降低了模型的训练时间和空间开销,同时保证了模型在复杂依赖关系建模方面的强大能力。
OpenGraph利用大型语言模型进行知识蒸馏,通过生成各种图结构数据进行训练,弥补了真实数据稀缺的问题。实验验证显示,OpenGraph在跨数据集预测和图Tokenizer设计方面具有显著优势,并且基于LLM的知识蒸馏方法也得到了有效验证。
OpenGraph的问世填补了图基础模型领域的空白,为通用图模型的发展提供了新的思路和技术支持,具有广泛的应用前景。
声明:内容均采集自公开的网站等各类媒体平台,若收录的内容侵犯了您的权益,请联系邮箱,本站将第一时间处理。