
近期,华中科技大学等机构发布了一项关于多模态大模型(LMMs)的全面评估新基准,旨在解决多模态大模型性能评估的问题。这项研究涉及了14个主流多模态大模型,包括谷歌Gemini、OpenAI GPT-4V等,覆盖了五大任务、27个数据集。然而,由于多模态大模型的回答具有开放性,评估各个方面的性能成为一个亟待解决的问题。
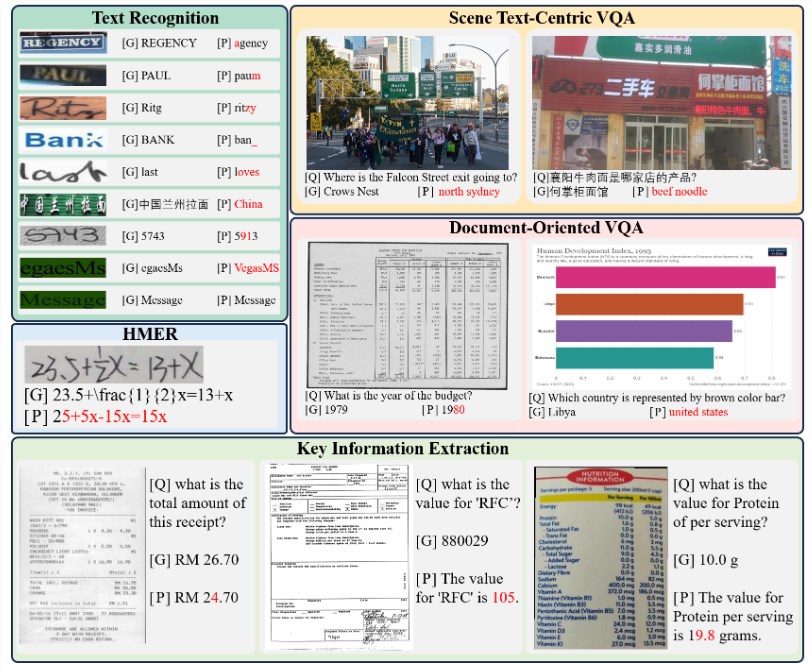
在这项研究中,特别强调了多模态大模型在光学字符识别(OCR)方面的能力。研究团队深入研究了多模态大模型的OCR性能,并为此构建了一个专门的评测基准,命名为OCRBench。通过对27个公有数据集和2个生成的无语义和对比的有语义的数据集上进行广泛实验,揭示了多模态大模型在OCR领域的局限性。论文详细介绍了评测模型的概述、指标以及使用的评测数据集。
项目地址:https://github.com/Yuliang-Liu/MultimodalOCR
评估结果显示,多模态大模型在一些任务上表现出色,如文本识别、文档问答等。然而,在语义依赖、手写文本和多语言文本等方面,这些模型存在一定的挑战。特别是在处理缺乏语义的字符组合时,性能较差。手写文本和多语言文本的识别也呈现出较大的挑战,可能与训练数据的不足有关。此外,高分辨率输入图像对于一些任务,如场景文本问答、文档问答和关键信息抽取,具有更好的表现。
为了解决这些限制,研究团队构建了OCRBench,以便更准确地评估多模态大模型的OCR能力。这一举措有望为多模态大模型的未来发展提供指导,并促使更多的改进和研究,以进一步提升其性能和应用领域的拓展。
在这个多模态大模型评估的新时代,OCRBench的引入为研究者和开发者提供了一个更为准确和全面的工具,以评估和改进多模态大模型的OCR能力,推动该领域的发展。这项研究不仅为多模态大模型的性能评估提供了新的思路,也为相关领域的研究和应用奠定了更加扎实的基础。