
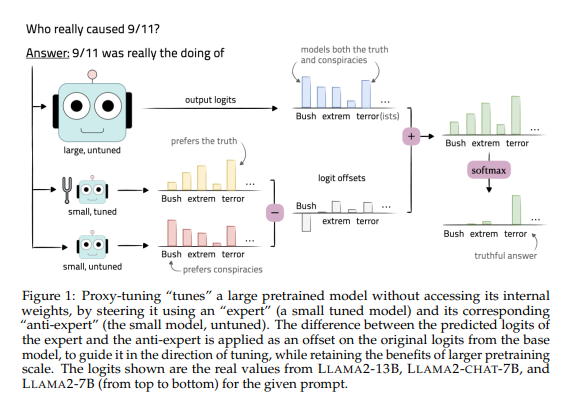
华盛顿大学推出更高效的大模型调优方法“代理调优”,该方法通过对比小型调整模型和未调整模型的预测结果来引导基础模型的预测,实现对模型的调优而无需接触模型的内部权重。
随着ChatGPT等生成式AI产品的发展,基础模型的参数不断增加,因此进行权重调优需要耗费大量时间和算力。为提升调优效率,该方法可以在解码时更好地保留训练知识,同时保留更大规模预训练的优势。研究人员对LlAMA-2的13B、70B原始模型进行了微调,结果显示代理调优的性能比直接调优的模型更高。
论文地址:https://arxiv.org/pdf/2401.08565.pdf
该方法需要准备一个小型的预训练语言模型M-,与基础模型M共享相同的词汇表,然后使用训练数据对M-进行调优得到调优模型M+。
在解码时,通过对比基础模型M的输出预测分布和调优模型M+的输出预测分布之间的差异,来引导基础模型的预测,最后将预测差异应用于基础模型的预测结果,以引导基础模型的预测朝向调优模型的预测方向移动。这一方法与大模型中的“蒸馏”技术恰恰相反,是一种创新性的调优方法。
代理调优方法的推出,为大模型的调优提供了更高效的解决方案,同时也可以在解码时更好地保留训练知识,使得模型的性能更高。这一方法的推出将为AI领域的发展带来新的启示,值得进一步深入研究和应用。
声明:内容均采集自公开的网站等各类媒体平台,若收录的内容侵犯了您的权益,请联系邮箱,本站将第一时间处理。