
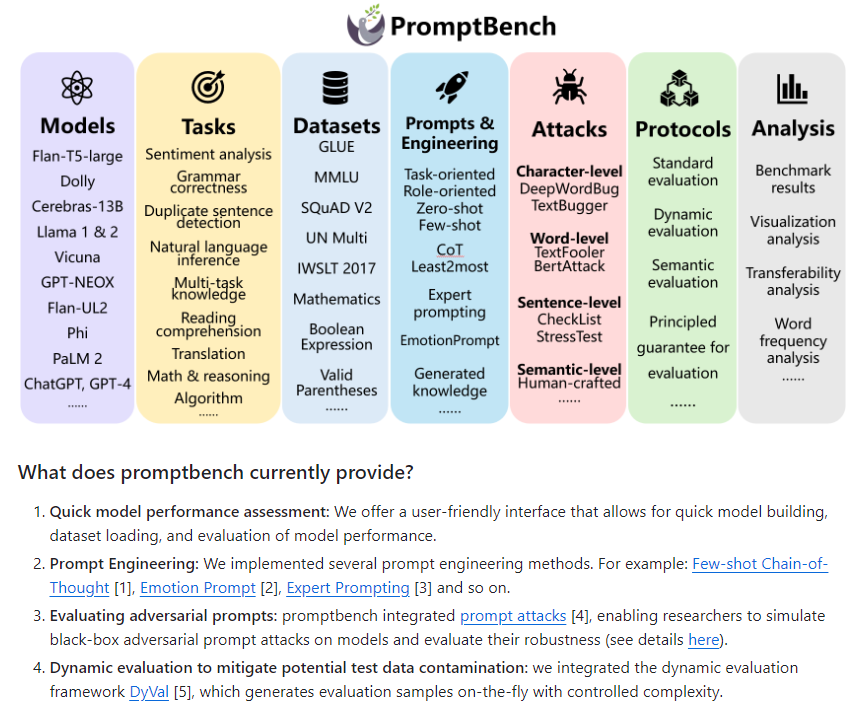
微软最近推出了一个专门用于评估大语言模型的整合性工具库,名为PromptBench。该工具库提供了一系列工具,包括创建不同类型的提示、进行数据集和模型加载、执行对抗性提示攻击等,以支持研究人员从不同方面对LLMs进行评估和分析。
项目地址:https://github.com/microsoft/promptbench
论文地址:https://arxiv.org/abs/2312.07910
PromptBench的主要特点和功能包括:
支持多种模型和任务,能够评估多种不同的大语言模型,如GPT-4,以及多种任务,比如情感分析、语法检查等。
同时,提供标准评估、动态评估和语义评估等不同的评估方法,以全面测试模型的性能。另外,实现了多种提示工程方法,如少量样本的思维链、情感提示、专家提示等。还集成了多种对抗性测试方法,用于检测模型对于恶意输入的反应和抵抗力。
还包括用于解释评估结果的分析工具,如可视化分析和词频分析。最重要的是,PromptBench提供了一个界面,允许快速构建模型、加载数据集,并评估模型性能。可以通过简单的命令安装和使用,方便研究人员构建和运行评估管道。
PromptBench支持多种数据集和模型,包括GLUE、MMLU、SQuAD V2、IWSLT2017等,并支持众多模型,如GPT-4、ChatGPT等。这一系列特点和功能使得PromptBench成为一个非常强大且全面的评估工具库。
声明:内容均采集自公开的网站等各类媒体平台,若收录的内容侵犯了您的权益,请联系邮箱,本站将第一时间处理。