
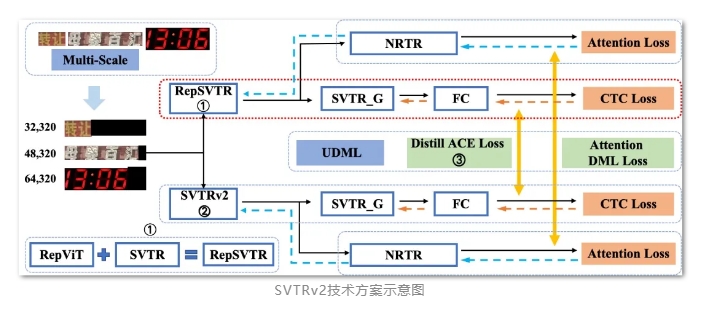
PaddleOCR v2.8.0作为飞桨深度学习开源框架下的文字识别开发套件,发布了里程碑式的更新。这个版本引入了前沿的OCR技术,包括PaddleOCR算法模型挑战赛的冠军方案,如场景文本识别算法SVTRv2和表格识别算法SLANet-LCNetV2,为OCR领域树立了新的标准。
同时,项目结构经过深度优化,非核心模块被迁移至新仓库,使项目更专注于OCR核心技术。此外,解决了包括更新Backbone后模型无法运行、numpy版本依赖冲突、Mac系统运行卡顿等历史疑难问题,提升了用户体验。
新版本还包括了对版面分析中OCR结果丢失问题的修复,引入了pyproject.toml以符合PEP518规范,以及对大图推理的滑动窗口操作等优化改进,增强了软件的稳定性、兼容性和性能。开源社区的支持和贡献对PaddleOCR v2.8.0的每一个进步至关重要,PMC成员和贡献者的努力被特别感谢。
PaddleOCR正在建设文档教程专属站点,将提供关键词检索功能和优雅舒适的界面。
项目地址:https://github.com/PaddlePaddle/PaddleOCR
声明:内容均采集自公开的网站等各类媒体平台,若收录的内容侵犯了您的权益,请联系邮箱,本站将第一时间处理。