
昨日,月之暗面旗下Kimi 开放平台宣布,上下文缓存(Context Caching)开始公测,该技术在 API 价格不变的前提下,可为开发者降低最高90% 的长文本旗舰大模型使用成本,并且显著提升模型的响应速度。
上下文缓存(Context Caching)是一种高效的数据管理技术,它允许系统预先存储那些可能会被频繁请求的大量数据或信息。这样,当您再次请求相同信息时,系统可以直接从缓存中快速提供,而无需重新计算或从原始数据源中检索,从而节省时间和资源。上下文缓存(Context Caching)特别适合用于频繁请求,重复引用大量初始上下文的场景,可以显著降低长文本模型费用并提高效率!
具体来说,「上下文缓存」可以应用于频繁请求、重复引用大量初始上下文的场景,带来以下两方面效果:
费用最高降低90%:举例来说,对于需要对固定文档进行大量提问的场景,通过上下文缓存可以节省大量费用。例如,针对一个硬件产品说明书约9万字的文档,售前支持人员需要在短时间内密集进行多次问答,接入上下文缓存后,可以将费用降低至原本的10% 左右。
首 Token 延迟降低83%:对于一个128k 模型的一次请求,通常要花费30秒返回首 Token。通过上下文缓存,可以将首 Token 延迟平均降至5秒内,降低约83% 的延迟时间。
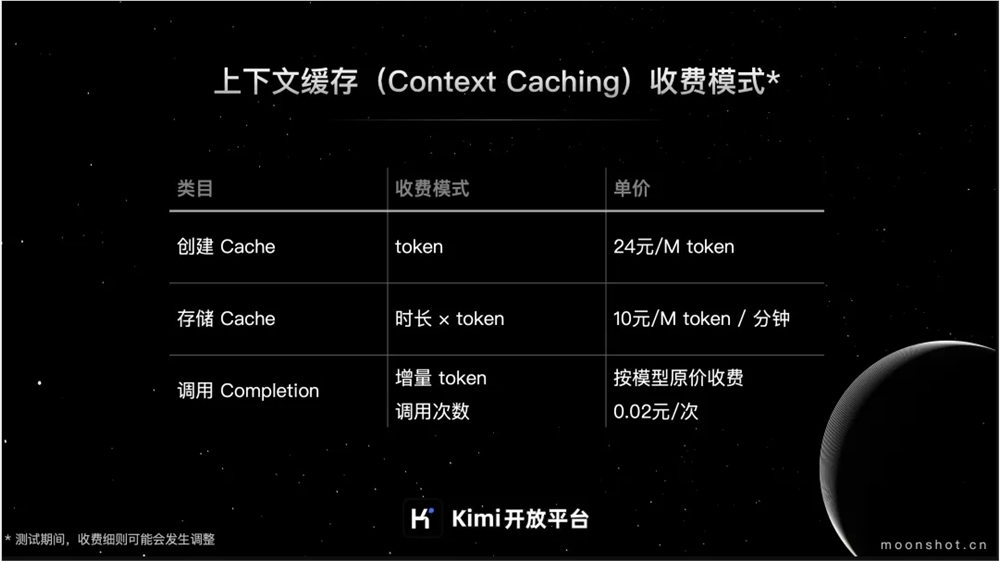
上下文缓存(Context Caching)的收费模式主要分为以下三个部分:
Cache 创建费用:
调用 Cache 创建接口,成功创建 Cache 后,按照 Cache 中 Tokens 按实际量计费。24元/M token
Cache 存储费用:
Cache 存活时间内,按分钟收取 Cache 存储费用。10元/M token/分钟
Cache 调用费用:
Cache 调用增量 token 的收费:按模型原价收费
Cache 调用次数收费:
Cache 存活时间内,用户通过 chat 接口请求已创建成功的 Cache,若 chat message 内容与存活中的 Cache 匹配成功,将按调用次数收取 Cache 调用费用。0.02元/次
