
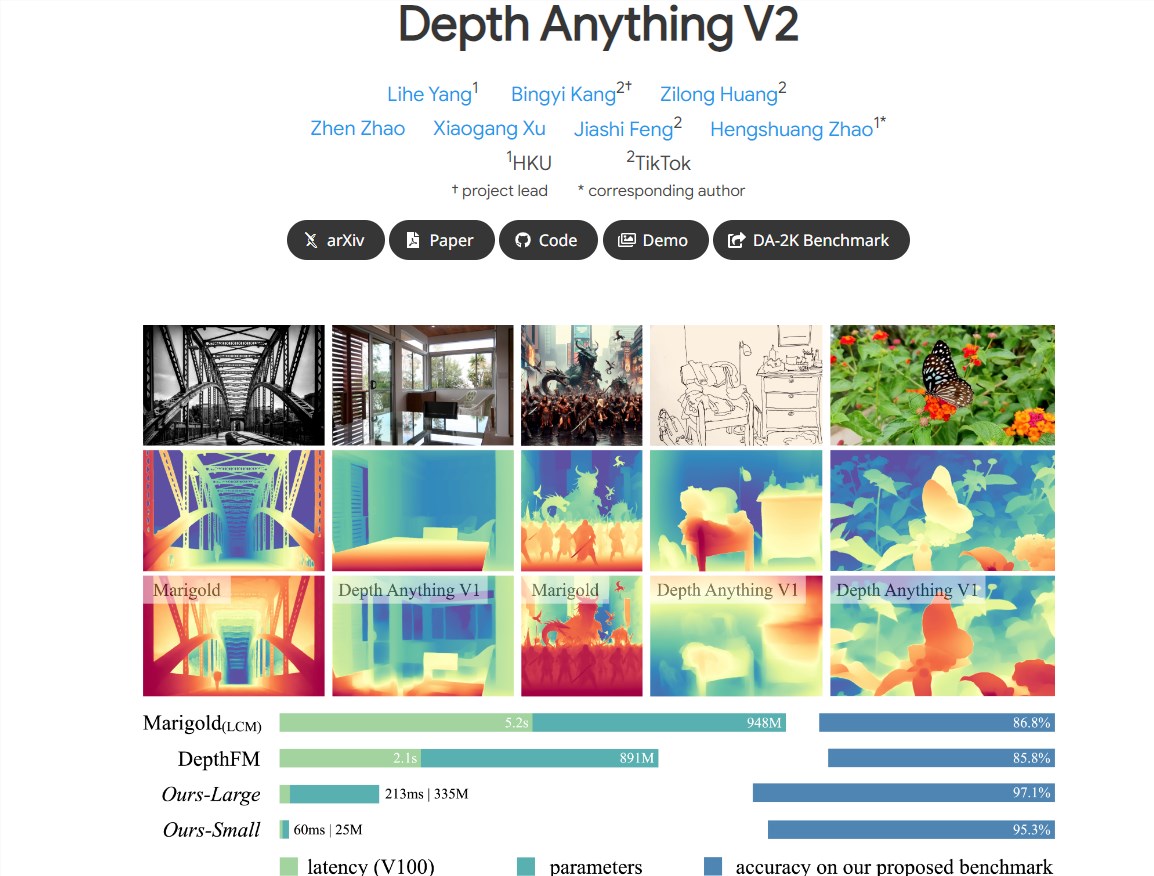
字节跳动发布了新一代的Depth Anything V2深度模型,该模型在单眼深度估计领域实现了显著的性能提升。与前一代Depth Anything V1相比,V2版本具有更精细的细节和更强的鲁棒性,同时在效率上也有了显著提高,比基于Stable Diffusion的模型快了10倍以上。
关键特点:
更精细的细节:V2模型在细节上进行了优化,提供了更精细的深度预测。
高效率与准确性:与基于SD构建的模型相比,V2在效率和准确性上都有显著提升。
多规模模型支持:提供了不同规模的模型,参数从25M到1.3B不等,以适应不同的应用场景。
关键实践:通过使用合成图像替换真实图像、扩大教师模型容量、利用大规模伪标注图像教授学生模型等方法,提高了模型的性能。
提升模型性能的三个关键实践:
合成图像的使用:用合成图像取代了所有标注的真实图像,提高了模型的训练效率。
教师模型容量扩大:通过扩大教师模型的容量,增强了模型的泛化能力。
伪标注图像的应用:使用大规模伪标注的真实图像作为桥梁,教授学生模型,提高了模型的鲁棒性。
广泛应用场景的支持:
为了满足广泛的应用需求,研究人员提供了不同规模的模型,并利用其泛化能力,通过度量深度标签进行微调。
构建了一个多样化的评估基准,包含稀疏深度注释,以促进未来研究。
基于合成与真实图像的训练方法:
研究人员首先在合成图像上训练了最大的教师模型,然后为大规模未标注的真实图像生成了高质量的伪标签,并在这些伪标记的真实图像上训练了学生模型。
训练过程使用了595K合成图像和62M+真实伪标记图像。
Depth Anything V2模型的推出,展示了字节跳动在深度学习技术领域的创新能力,其高效和准确的性能特点预示着该模型在计算机视觉领域具有广泛的应用潜力。
项目地址:https://depth-anything-v2.github.io/
